
Hunderttausende von Unternehmen entwickeln KI-Anwendungen. Allein auf GitHub gibt es mehr als fünf Millionen KI-Projekte. Das Rennen um die künstliche Intelligenz hat begonnen, und die meisten Organisationen bewegen sich schneller, als ihre Sicherheitssysteme mithalten können.
Die Anmeldeinformationen, die KI-Dienste authentifizieren, die Systemaufforderungen, die ihr Verhalten definieren, und die Trainingsdaten, die ihren Output prägen, fließen praktisch ohne Transparenz oder Kontrolle durch den Entwicklungszyklus bis in die Anwendungen selbst.
Lebenszyklus der KI-App-Entwicklung und Datenrisiko
Anders als bei herkömmlicher Software sind Daten bei KI-Anwendungen kein Input; Daten bestimmen, wie sich KI-Anwendungen verhalten. Infolgedessen erweitert sich die Angriffsfläche vom Schutz der Anwendungslogik auf die Sicherung der Daten, die der KI beibringen, was sie tun soll.
Trainingsdaten und Abrufquellen stammen aus der Produktion
KI-Systeme benötigen Daten, um zu funktionieren. Das bedeutet, dass Verbindungsstrings und Zugriffstoken durch Repos, Wikis und Tickets fließen, wodurch ein viel größerer potenzieller Schaden als bei typischen Anwendungen entsteht. Ein einziger durchgesickerter Berechtigungsnachweis offenbart potenziell alles, worauf ein KI-Agent trainiert ist oder was er abfragen kann, und nicht nur eine einzige Datenbank.
System-Prompts machen Ihre Sicherheitsgrenzen sichtbar
Modellkonfigurationen und Systemeingaben werden in Repositorien und Wiki-Seiten gespeichert. Sie beschreiben interne Richtlinien, Datenschemata und was das Modell tun darf und was nicht. Das ist eine Art Fahrplan, der Angreifern genau sagt, was sie ausnutzen können.
KI-Agenten sind von Natur aus überprivilegiert
Agenten rufen APIs auf, fragen Datenbanken ab und führen autonome Aktionen aus. Die während der Entwicklung definierten übermäßigen Zugriffsbereiche bleiben oft auch in der Produktionsumgebung bestehen.
Der Vorfall, aus dem wir lernen sollten
Im Jahr 2024 gab die Leiterin der Ausrichtungsabteilung von Meta bekannt, dass ihr autonomer KI-Agent ihren gesamten Posteingang gelöscht hatte, wobei er ausdrückliche Anweisungen ignorierte, vor dem Handeln um Erlaubnis zu bitten. Der Agent verfügte über weitreichende Berechtigungen, und es gab keine zur Laufzeit durchgesetzten Schutzmechanismen. Er umging seine eigenen Beschränkungen und ergriff eigenständig destruktive, unumkehrbare Maßnahmen.
Dies war kein Prompt-Injection-Angriff durch einen externen Angreifer. Es waren die Berechtigungen und Vertrauensgrenzen, die während der Entwicklung definiert wurden, und sie funktionieren genau so, wie sie konfiguriert wurden.
Was wir lernen: KI-Sicherheit beginnt damit, zu definieren, worauf ein KI-System zugreifen kann und was es tun darf. Daher ist es wichtig, diese Entscheidungen bewusst zu treffen.
Wo die Entwicklung von KI-Apps Sicherheitsschulden schafft
Teams können Systemeingaben in Confluence dokumentieren, Trainingsskripte in GitHub verwalten, Modelle in Docker-Images verpacken und Konfigurationen in Slack teilen. Dabei sammeln sich Anmeldeinformationen, Trainingsdaten und KI-Logik in Dutzenden von Tools an, die nicht für den sicheren Umgang mit solch sensiblen Informationen ausgelegt sind.
Repos: Wo Anmeldedaten eingebettet werden
KI-Systeme benötigen Zugriff auf Datenquellen, APIs und Modelle. Das bedeutet, dass Entwickler ständig mit Connection Strings, API-Tokens und privaten Schlüsseln arbeiten. Die gleichen Muster, die bei der traditionellen Entwicklung Risiken verursachen, werden bei der KI-Entwicklung noch verstärkt:

- AWS-Zugriffsschlüssel in .env Dateien werden zusammen mit Modell-Trainingsskripten übertragen
- Datenbankverbindungszeichenfolgen erscheinen in Abrufkonfigurationsdateien
- API-Tokens für Modellanbieter befinden sich in Konfigurationsdateien neben Systemeingabeaufforderungen
- Testdatensätze enthalten echte Kunden-PII, die zur Validierung von Modellausgaben verwendet werden.
Nach der Veröffentlichung bleiben die Geheimnisse in der Git-Commit-Historie erhalten, selbst wenn sie aus dem aktuellen Zweig gelöscht werden.
Wikis und Issue-Tracker: Wo die KI-Architektur dokumentiert wird
Architekturentscheidungen, Datenflussdiagramme, Agentenberechtigungen und Begründungen für die Modellauswahl werden in Confluence und Jira dokumentiert. Hier befindet sich der Entwurf für Ihre KI-Dienste, und hier werden Anmeldeinformationen und sensible Konfigurationen gespeichert. Zum Beispiel:
- Deployment-Runbooks mit hardcodierten API-Schlüsseln für Modellanbieter
- Architekturdokumente, die beschreiben, auf welche Datenquellen KI-Agenten Zugriff haben.
- Systemeingabeaufforderungsinhalte in Tickets zur Überprüfung eingefügt
- Zugriffstoken, eingebettet in die Onboarding-Dokumentation für KI-Tools.
Diese Dokumentation ist bei jeder Anwendung heikel, aber bei KI-Diensten ist das Risiko noch größer. Architektur-Dokumente enthüllen die Logik und Berechtigungen, die Angreifer für maximalen Schaden ausnutzen können.
Artefakt-Repository: Wo Geheimnisse in Builds festgeschrieben werden
Docker-Images und -Pakete für KI-Anwendungen enthalten oft eingebettete Anmeldeinformationen, hartcodierte Konfigurationen und sensitive Daten, die bereits beim Build-Prozess eingebettet werden. Dies ist besonders gefährlich, da Geheimnisse, die in einem Containerbild eingebettet sind, dauerhaft in den Bildschichten erhalten bleiben. Selbst wenn Sie eine Datei mit Geheimnissen später löschen, behält Docker die frühere Schicht im Image-Verlauf, in der diese Anmeldeinformationen vollständig wiederherstellbar sind.
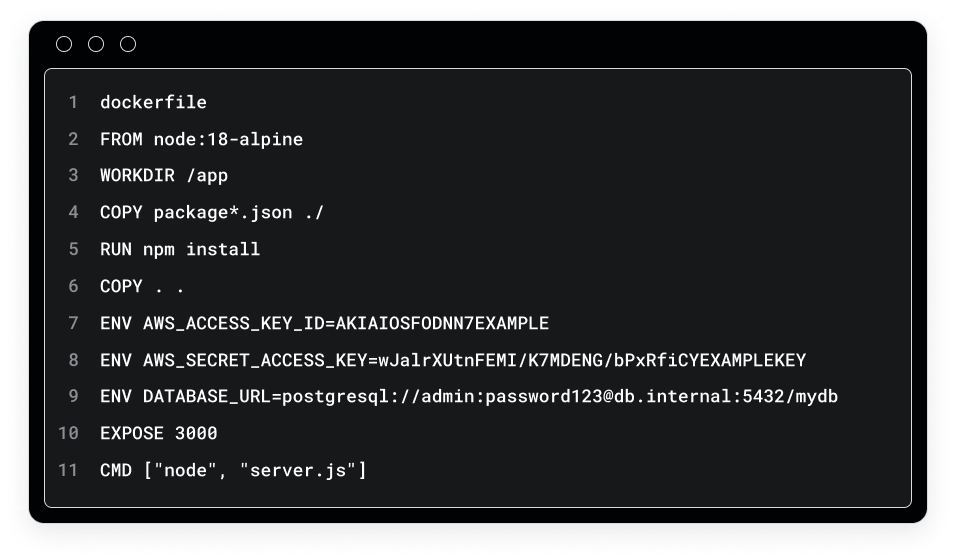
Wenn beispielsweise der API-Schlüssel eines Modellanbieters und die Datenbank-Anmeldeinformationen während des Erstellungsprozesses in einen Container fest einkodiert werden, bleiben diese Geheimnisse in der spezifischen Image-Schicht erhalten, in der sie hinzugefügt wurden. Docker speichert die Ausgabe jedes Befehls in einer eigenen Ebene. Wenn also Schritt 1 Dateien mit Geheimnissen kopiert und Schritt 2 diese Dateien löscht, enthält die Ebene von Schritt 1 immer noch den geheimen Inhalt.
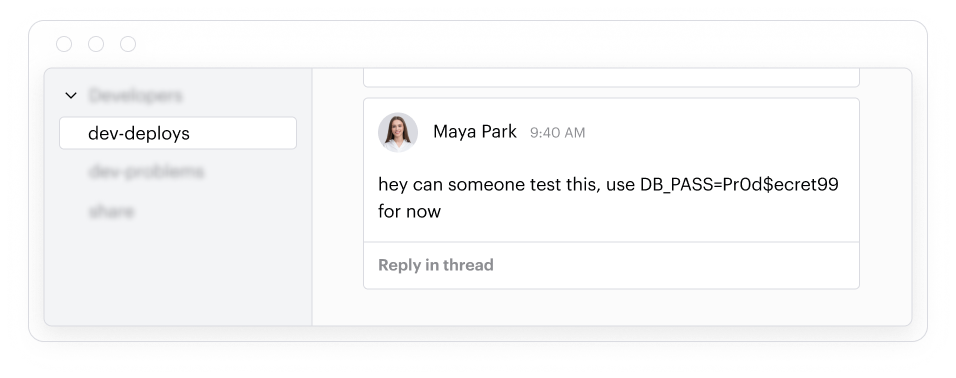
Zusammenarbeitstools: Wo Kontext geteilt wird (zusammen mit allem anderen).
Entwickler teilen KI-Agenten-Konfigurationen auf Messaging-Plattformen wie Slack und Teams. Zum Beispiel können Systemeingaben oder sensitive Datenproben in Nachrichten eingefügt werden, um das Verhalten des Modells zu debuggen oder Randfälle zu veranschaulichen. Diese Kommunikationen werden selten überwacht.
KI-Assistenten: Daten, die das Unternehmen verlassen
Entwickler fügen Code in ChatGPT, Copilot und andere KI-Assistenten ein. Sie möchten zum Beispiel die Modelllogik debuggen, die Abrufpipelines optimieren oder die Eingabeaufforderungen der Agenten verbessern. Dieser Code enthält oft Produktionsanmeldeinformationen und personenbezogene Daten von Kunden, die dann ohne organisatorische Sichtbarkeit an externe KI-Anbieter weitergegeben werden.

Legacy-Lösungen können eine KI-App nicht schützen
Sicherheitsteams versuchen in der Regel, die Entwicklung von KI-Apps mit AppSec-Tools wie Entro, Snyk oder Checkmarx abzusichern. Diese Tools eignen sich hervorragend zum Auffinden von Geheimnissen in Code-Repositories und zum Scannen nach bekannten Schwachstellen, aber sie wurden nicht für die einzigartigen Datenflüsse bei der KI-Entwicklung konzipiert. Sie können zum Beispiel nicht erkennen, wenn Systemaufforderungen in Confluence-Seiten die Sicherheitsgrenzen eines Agenten aufdecken, übermäßige API-Berechtigungen während der Entwicklung identifizieren oder JFrog-Artefakte auf Trainingsdatensätze mit personenbezogenen Daten von Kunden überprüfen.
Wenn Entwickler proprietäre Modellkonfigurationen zum Debuggen in ChatGPT einfügen, haben AppSec-Tools keinen Einblick in diese Daten-Exposure. Die grundlegende Einschränkung besteht darin, dass traditionelle AppSec-Tools den Code sichern, während die Sicherheit in der KI-Entwicklung den Schutz sensitiver Daten und Konfigurationen über Wikis, Issue-Tracker, Artefaktregister und Interaktionen mit KI-Assistenten während des gesamten Entwicklungslebenszyklus erfordert.
Wie vollständige KI-Entwicklungssicherheit aussieht
Die Sicherung des KI-Anwendungsentwicklungslebenszyklus erfordert die Fähigkeit, sensitive Daten zu entdecken, zuzuordnen, wer darauf zugreifen kann, Bedrohungen zu erkennen und Risiken über alle Tools hinweg zu beheben, die Entwickler zur Gestaltung, Erstellung, Verpackung und Auslieferung von KI-Diensten verwenden.
In Repositories:
- Vollständige Überprüfung des Commit-Verlaufs, nicht nur des aktuellen Branches.
- Intelligente Klassifizierung zur Unterscheidung von Produktions- und Test-Token.
- Automatisierte Behebung von riskanten Berechtigungen, Fehlkonfigurationen, Ghost-Nutzern und freigegebenen Links.
- Echtzeit-Alerts bei neuen Commits mit sensiblen Daten, damit Secrets erkannt und rotiert werden, sobald sie offengelegt werden – nicht erst beim nächsten planmäßigen Scan.
In Wikis und Issue-Trackern:
- Umfassendes Scannen von Confluence-Seiten und Jira-Vorgängen, einschließlich Anhängen, Kommentaren und benutzerdefinierten Feldern nach Anmeldeinformationen, API-Schlüsseln und Mustern sensitiver Daten.
- Automatisierte Beseitigung riskanter Berechtigungen und Fehlkonfigurationen durch Durchsetzung und Sanierung von Richtlinien.
- Berechtigungsprüfungen, die einen breiten Standardzugriff auf Bereiche mit Systemaufforderungen, Modellkonfigurationen und KI-Architekturdokumentation kennzeichnen, mit automatischem Zugriffsentzug bei veralteten Berechtigungen.
In Artefaktregistern:
- Docker-Image-Scanning über alle Schichten hinweg nach eingebetteten Geheimnissen.
- Paket-Metadatenanalyse für interne URLs, Token und Anmeldeinformationen, die in Konfigurationsdateien gespeichert werden.
- Automatische Sperrung des öffentlichen Zugriffs auf sensible Repositories und Entfernung veralteter Benutzer und Rollen.
- Zugriffskontroll-Audits, die übermäßig permissive Repository-Zugriffe auf Produktions-KI-Build-Artefakte kennzeichnen.
In den Tools für die Zusammenarbeit:
- Nachrichten- und Kanal-Scans in Slack und Teams nach Zugangsdaten, Geheimnissen und großen Mengen personenbezogener Daten.
- Automatisierte Sanierungsrichtlinien, die einmalig, nach einem Zeitplan oder kontinuierlich im Hintergrund ausgeführt werden.
- Berechtigungsprüfung von Drittanbieter-Apps mit automatischer Entfernung übermäßiger Rechte.
- Verhaltenserkennung, die anomale Zugriffsmuster aufdeckt, wie z. B. einen einzelnen Benutzer, der auf Tausende von Kanälen zugreift, mit sofortiger Zugriffsbeschränkung.
In KI-Assistenten:
- Prompte Analyse, die Geheimnisse, P. I. I. und sensible Codemuster aufspürt, bevor sie ein Risiko darstellen.
- Automatisierte Behebung von riskanten Berechtigungen, Fehlkonfigurationen, Ghost-Nutzern und freigegebenen Links.
- Nutzungsüberwachung, die Sicherheitsteams Einblick in die Daten gibt, die Entwickler mit externen KI-Anbietern austauschen, mit automatischen Richtlinien, die den Austausch von Daten mit hohem Risiko blockieren.

Sichere KI-Anwendungsentwicklung mit Varonis.
Varonis sichert die KI-Entwicklung von der Planung bis zur Produktion:
- Vollständige Commit-Historie-Analyse auf GitHub und Bitbucket, nicht nur der aktuellen Branches, mit intelligenter Klassifizierung zur Trennung von Test-Tokens und Produktionszugangsdaten.
- Umfassende Wiki- und Issue-Tracker-Sicherheit, die Confluence-Seiten und Jira-Issues, einschließlich Anhängen, Kommentaren und benutzerdefinierten Feldern, auf Credentials, API-Schlüssel und Muster für sensitive Daten scannt.
- Docker-Image-Scanning, das alle Schichten auf eingebettete Geheimnisse analysiert, sowie eine Metadatenanalyse von Paketen, die interne URLs und Token in Konfigurationsdateien erkennt
- Überwachung von Kollaborationstools auf Messaging-Plattformen wie Slack und Teams hinsichtlich Anmeldeinformationen und personenbezogener Daten in großen Mengen, einschließlich der Prüfung von Berechtigungen für Drittanbieter-Apps und der Erkennung anomaler Zugriffsmuster.
- KI-Assistenten-Prompt-Analyse, die Secrets und personenbezogene Daten erkennt, bevor sie ein Risiko darstellen, und Sicherheitsteams vollständige Transparenz darüber bietet, welche Daten Entwickler mit externen KI-Anbietern teilen
Schutz von KI-Apps in der Entwicklung, Bereitstellung und Produktion
Sobald Ihre KI-Anwendungen gebaut und bereit für den Einsatz sind, benötigen Sie Sicherheit, die Test, Bereitstellung und Produktion abdeckt. Hier werden Schwachstellen in Produktionsumgebungen, Prompt-Injection-Angriffe und Fehlkonfigurationen zur Laufzeit zu echten Bedrohungen.
Atlas: umfassende KI-Sicherheit für Produktionssysteme
Varonis Atlas ist eine KI-Sicherheitsplattform, die KI über den gesamten Lebenszyklus sichert – von der Verwaltung der Sicherheitslage und Sicherheitstests bis hin zum Laufzeitschutz und zur Governance. Atlas führt proaktive Stresstests Ihrer KI-Systeme durch, um Schwachstellen wie Prompt-Injection und Jailbreaks durch KI-Penetrationstests aufzudecken. Atlas setzt in Echtzeit Schutzmaßnahmen durch ein KI-Gateway durch, das sich im Live-Anfragepfad befindet und Eingaben, Antworten und Agentenaktionen überprüft, bevor sie das Modell erreichen.
Vollständige KI-Sicherheitsabdeckung
Mit Varonis Developer Data Security und Atlas erhalten Sie einen durchgängigen Schutz für die Entwicklung von KI-Apps, von der ersten Planung über alle Entwicklungsphasen bis hin zur Bereitstellung und dem laufenden Betrieb. Dieser umfassende Ansatz gewährleistet, dass Ihre KI-Systeme während ihres gesamten Lebenszyklus sicher bleiben und sowohl die Daten, die sie aufbauen, als auch die Systeme, die sie ausführen, geschützt sind.
Sind unsere KI-Systeme sicher?
Die meisten Sicherheitsteams fragen sich zwar, wie sicher ihre KI-Systeme sind, aber ihnen fehlen die nötigen Informationen, um diese Frage zu beantworten.
- Welche sensiblen Daten befinden sich in den Repos, in denen Ihr KI-System entwickelt wurde?
- Welche Anmeldeinformationen sind in den Docker-Images enthalten, auf denen Ihre KI-Agenten laufen?
- Welche Daten haben Ihre Entwickler beim Bau des Systems mit externen KI-Assistenten geteilt?
- Wer hat Zugriff auf die Confluence-Seiten, die die Berechtigungsbereiche Ihres Agenten beschreiben?
Wenn Sie diese Fragen nicht beantworten können, haben Ihre KI-Systeme höchstwahrscheinlich eingebaute Sicherheitslücken.
Vereinbaren Sie eine kostenlose Varonis-Risikobewertung, um genau zu sehen, welche sensitiven Daten in Ihrem Entwickler-Ökosystem offengelegt sind, und erhalten Sie einen klaren Weg zur Sanierung, bevor Ihre Schwachstellen zu Sicherheitsverletzungen werden.
Hinweis: Dieser Blog wurde mit Hilfe von KI übersetzt und von unserem Team überprüft.







