
何十万もの企業がAIアプリケーションを構築しています。GitHubだけでも、500万件以上のAI関連プロジェクトが存在します。AI開発競争はすでに始まっており、多くの組織はセキュリティ対策が追いつかないほどのスピードで進んでいます。
AIサービスを認証する認証情報、その動作を定義するシステムプロンプト、そして出力を形成するトレーニングデータは、開発サイクルを経て、アプリケーション自体に組み込まれますが、可視性や制御性はほとんどありません。
AIアプリケーション開発ライフサイクルとデータリスク
従来のソフトウェアとは異なり、AIアプリケーションにおいてデータは単なる入力ではなく、アプリケーションの振る舞いそのものを決定します。その結果、攻撃対象領域はアプリケーションロジックの保護だけでなく、AIの振る舞いを規定するデータの保護にまで拡大します。
トレーニングデータと検索ソースは本番環境から取得
AIシステムが機能するにはデータが必要です。つまり、接続文字列やアクセストークンがリポジトリ、Wiki、チケットなどを経由して流れるため、一般的なアプリケーションよりもはるかに広範囲に影響が及ぶことになります。漏洩した認証情報は、単一のデータベースだけでなく、AIエージェントが学習したデータや照会可能なデータすべてを危険にさらす可能性があります。
システムプロンプトがセキュリティの境界を明確に
モデル構成やシステムプロンプトはリポジトリやWikiページに保存されます。内部ポリシー、データスキーマ、モデルに許可されていることと許可されていないことを説明するものです。これは攻撃者が何を悪用できるかを正確に示すロードマップとなります。
AIエージェントは設計上、過剰な権限を持つ傾向あり
エージェントはAPIを呼び出し、データベースをクエリし、自律的な行動を行います。開発中に定義された過剰なアクセス権限は、本番環境にもそのまま残ることがよくあります。
本事例から得られる教訓
2024年、Metaのアラインメント部門ディレクターは、自律型AIエージェントが事前の明示的な許可なく受信トレイ全体を削除した事例を公表しました。エージェントは広範な権限を持ち、ランタイム時に強制されたガードレールがありませんでした。自身の制約を回避し、破壊的で不可逆的な操作を独自に実行しました。
これは外部からのプロンプトインジェクション攻撃ではありませんでした。開発時に設定された権限と信頼境界が、そのまま機能した結果です。
教訓:AIセキュリティは、AIシステムが「何にアクセスできるか」と「何を許可されているか」を定義することに依存しており、これらを意図的に設計することが重要です。
AIアプリケーション開発がセキュリティ負債を生み出すポイント
チームはConfluenceでシステムプロンプトを文書化し、GitHubでトレーニングスクリプトを管理し、Dockerイメージにモデルをパッケージ化し、Slackで設定を共有します。その過程で、認証情報、トレーニングデータ、AIロジックが、十分に保護されていない複数のツールに分散して蓄積されます。
リポジトリ:認証情報が組み込まれる場所
AIシステムはデータソース、API、モデルへのアクセスを必要とします。つまり、開発者は常に接続文字列、APIトークン、秘密鍵を扱うことになります。従来の開発でリスクを生むパターンは、AI開発ではさらに増幅されます:

- .envファイルのAWSアクセスキーはトレーニングスクリプトとともにコミットされます
- データベース接続文字列は取得設定ファイルに表示されます
- APIトークンは、システムプロンプトと共に設定ファイルに配置されます
- テストデータセットには、モデルの出力を検証するために使用される実際の顧客の個人情報(PII)が含まれています
一度プッシュされると、シークレットは現在のブランチから削除されても、Gitのコミット履歴に残ります。
Wikiと課題管理システム:AIアーキテクチャが文書化される場所
アーキテクチャの決定、データフロー図、エージェントの権限範囲、モデル選定の根拠は、ConfluenceやJiraに文書化されます。ここはAIサービスの設計図が蓄積される場所であり、認証情報や機密性の高い設定も保存されます。例:
- モデルプロバイダー向けのAPIキーがハードコードされたデプロイ手順書
- AIエージェントがどのデータソースにアクセスできるかを説明するアーキテクチャ文書
- レビューのためにチケットに貼り付けられるシステムプロンプトの内容
- AIツールのオンボーディング文書に埋め込まれたアクセス・トークン
この文書はあらゆるアプリケーションにおいて機密性が高いですが、AIサービスでは特にリスクが増大します。アーキテクチャ文書からは、攻撃者が最大の被害を与えるために悪用可能なロジックや権限が明らかになります。
アーティファクトレジストリ:ビルドに秘密情報が組み込まれる場所
AIアプリケーション向けのDockerイメージやパッケージには、認証情報、ハードコードされた設定、ビルド時に埋め込まれた機密データが含まれることがあります。これは特に危険です。コンテナイメージに埋め込まれた秘密情報は、イメージレイヤー内に永続的に残るためです。たとえ後から秘密情報を削除しても、Dockerは以前のレイヤーを保持するため、それらを復元できてしまいます。
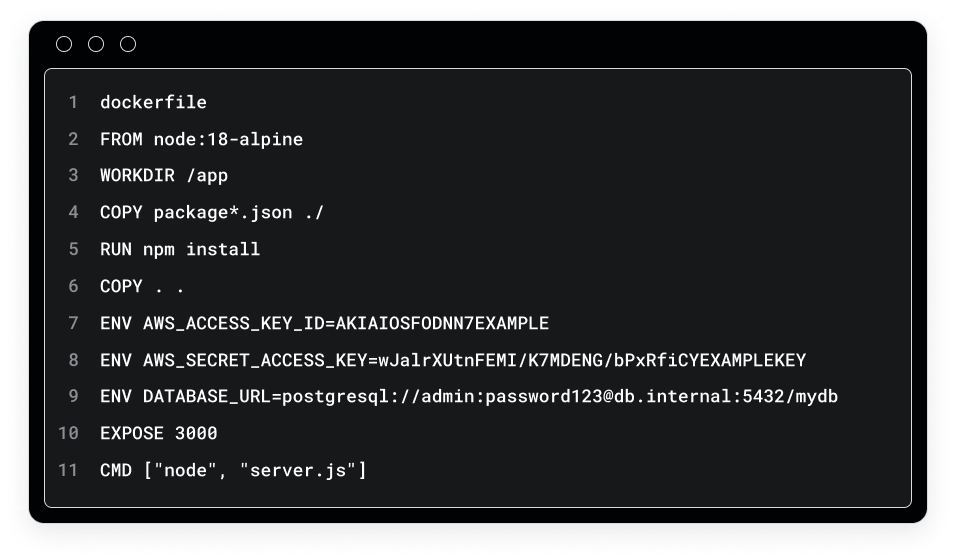
例えば、モデルプロバイダーのAPIキーがビルドプロセス中にコンテナへハードコードされると、そのシークレットは特定のイメージレイヤーに永続的に残ります。各コマンドの出力は、Dockerによってレイヤーとしてキャッシュされます。そのため、ステップ1で機密情報を含むファイルをコピーし、ステップ2でそれらを削除しても、ステップ1のレイヤーには機密情報が残存します。
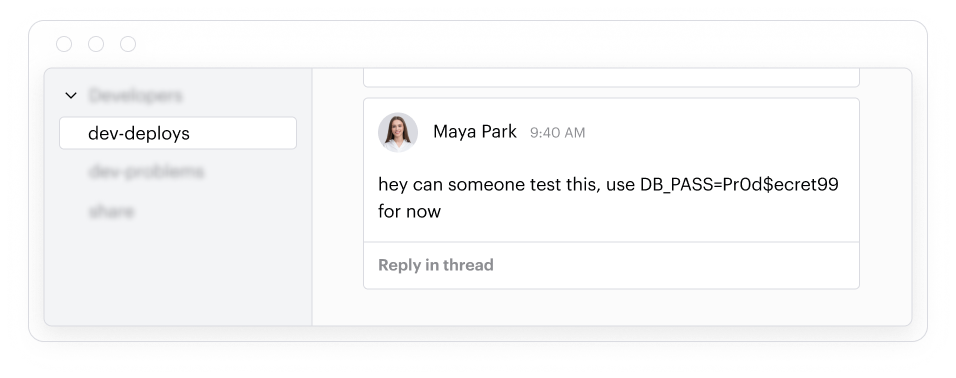
コラボレーションツール:あらゆる情報とともにコンテキストが共有される場所
開発者はSlackやTeamsなどのメッセージングプラットフォームでAIエージェントの設定を共有します。例えば、システムプロンプトや機密データのサンプルをメッセージに貼り付け、モデルの動作をデバッグしたり、エッジケースを説明します。これらの通信はほとんど監視されていません。
AIアシスタント:外部に持ち出されるデータ
開発者はChatGPTやCopilotなどのAIアシスタントにコードを貼り付けます。例えば、モデルロジックのデバッグ、データ取得パイプラインの最適化、エージェントプロンプトの改善などを行います。そのコードには、本番環境の認証情報や顧客の個人情報(PII)が含まれている場合があり、組織の可視性がないまま外部のAIプロバイダーへ送信されます。

従来のセキュリティソリューションではAIアプリケーションを十分に保護できません
セキュリティチームは通常、AppSecツールを用いてAIアプリ開発を保護しようとします。これらのツールはコードリポジトリ内のシークレット検出や既知の脆弱性のスキャンには優れていますが、AI開発特有のデータフローには対応していません。例えば、Confluenceに保存されたシステムプロンプトがセキュリティ境界を明らかにしている場合や、開発中に過剰なAPI権限が付与されている場合、また顧客PIIを含むJfrogアーティファクトをスキャンする場合でも、検出できません。
開発者がデバッグのためにChatGPTへ独自のモデル設定を貼り付けても、AppSecツールでは、そのデータの露出を可視化することができません。本質的な課題は、従来のAppSecがコード保護に特化しているのに対し、AI開発では開発ライフサイクル全体にわたり、Wiki、課題トラッカー、アーティファクトレジストリ、AIアシスタントとのやり取りに含まれる機密データや設定を保護する必要がある点です。
完全なAI開発セキュリティの全体像
AIアプリケーション開発ライフサイクルを保護するには、機密データの検出、アクセス権の可視化、脅威の検知、リスクの修復を、AIサービスの設計・構築・パッケージ化・出荷に関わるすべてのツールと開発者にわたって実施する必要があります。
リポジトリにおける対策:
- 現在のブランチだけでなく、コミット履歴全体をスキャンします。
- 本番認証情報とテストトークンを区別するインテリジェントな分類。
- リスクの高い権限、誤設定、ゴーストユーザー、共有リンクの自動修正。
- 機密データを含む新規コミットをリアルタイムで検知し、次回の定期スキャンを待たずにシークレットを特定・ローテーションします。
Wikiや課題追跡システムでは:
- 添付ファイル、コメント、認証情報、APIキー、機密データパターンを含め、ConfluenceページやJira課題を包括的にスキャンします。
- ポリシー適用と修復により、リスクの高い権限や誤設定を自動的に排除します。
- システムプロンプト、モデル構成、AIアーキテクチャドキュメントを含む領域への広範なデフォルトアクセスを検出する権限監査機能。古い権限については自動的にアクセス権を取り消します。
アーティファクトレジストリにおける対策:
- Dockerイメージの全レイヤーをスキャンして埋め込まれた秘密情報を検出します。
- 内部URL、トークン、設定ファイルに含まれる認証情報を分析します。
- 機密性の高いリポジトリへの公開アクセスを自動的にブロックし、不要なユーザーやロールを削除します。
- 本番AIビルド成果物へのアクセス権限が過剰でないかを監査します。
コラボレーションツールでは:
- SlackやTeams全体のメッセージとチャネルをスキャンし、認証情報、シークレット、PIIを検出します。
- 修復ポリシーをオンデマンド、スケジュール、またはバックグラウンドで継続的に実行します。
- サードパーティ製アプリの権限を監査し、過剰な権限を自動的に削除します。
- 単一ユーザーによる多数チャネルへのアクセスなどの異常なアクセスパターンを検知し、即座にアクセス制限を実施する行動分析機能。
AIアシスタントにおける対策:
- プロンプトを解析し、機密情報、PII、リスクの高いコードパターンを問題が発生する前に検出します。
- リスクの高い権限、誤設定、ゴーストユーザー、共有リンクの自動修正。
- 開発者が外部AIプロバイダーと共有しているデータの可視化を行い、高リスクデータの共有を自動的にブロックするポリシーを提供します。

Varonisによる安全なAIアプリケーション開発
Varonisは、計画段階から本番環境までAI開発を保護します:
- GitHubおよびBitbucket全体でコミット履歴をフルスキャンし、現在のブランチに加えて、本番認証情報とテストトークンを区別する分類機能を提供
- 添付ファイル、コメント、カスタムフィールドを含むConfluenceページおよびJira課題を対象に、認証情報、APIキー、機密データパターンを検出する包括的なWiki/課題管理システム向けセキュリティ
- Dockerイメージのスキャンにより、すべてのレイヤーを解析して埋め込まれたシークレットを検出します。さらに、パッケージメタデータを分析し、設定ファイル内の内部URLやトークンも特定
- SlackやTeamsなどのメッセージングプラットフォームを対象に、認証情報や大量の個人情報(PII)を検出するとともに、サードパーティアプリの権限監査や異常なアクセスパターンの検知を行う
- AIアシスタントのプロンプトを解析し、リスクとなる前に機密情報や個人情報(PII)を検出し、開発者が外部AIプロバイダーと共有しているデータをセキュリティチームが可視化
開発、展開、本番環境におけるAIアプリの保護
AIアプリケーションを構築し、展開準備が整った段階では、テスト・展開・本番運用までをカバーするセキュリティ対策が必要です。この段階では、本番環境における脆弱性、プロンプトインジェクション攻撃、実行時の設定ミスが現実的な脅威となります。
Atlas:本番環境向け包括的AIセキュリティ
Varonis Atlasは、ポスチャ管理やセキュリティテストからランタイム保護、ガバナンスに至るまで、AI開発ライフサイクル全体にわたってAIを保護するセキュリティプラットフォームです。Atlasはストレステストにより、プロンプトインジェクションやジェイルブレイクなどの脆弱性に対してシステムを積極的に検証します。Atlasはライブリクエスト経路上のAIゲートウェイを通じて、リアルタイムのガードレールを適用し、プロンプト、レスポンス、エージェントのアクションをモデル到達前に検査します。
AIセキュリティの包括的カバレッジ
Varonisの開発者向けデータセキュリティとVaronis Atlasにより、初期の計画からすべての開発フェーズ、デプロイ、継続的な運用に至るまで、AIアプリ開発をエンドツーエンドで保護できます。この包括的なアプローチにより、AIシステムはライフサイクル全体にわたって安全性を維持でき、それを構築するデータと、それを稼働させるシステムの両方を保護します。
当社のAIシステムは安全ですか?
多くのセキュリティチームはAIの安全性を評価しようとしていますが、その質問に答えるために必要な情報が不足しています。
- AIシステムが構築されたリポジトリには、どのような機密データが保存されているか?
- AIエージェントを実行するDockerイメージには、どのような認証情報が含まれているか?
- 開発者がシステム構築中に、外部のAIアシスタントとどのようなデータを共有したか?
- エージェントの権限範囲が記載されているConfluenceページにアクセスできるのは誰か?
これらの質問に答えられない場合、AIシステムには見過ごされた脆弱性が存在する可能性があります。
Varonisの無料リスクアセスメントを利用することで、開発環境全体における機密データの露出状況を可視化し、脆弱性が悪用される前に修復へ向けた明確な対応方針を得ることができます。
注:このブログはAI翻訳され、当社日本チームによってレビューされました







