
Data security is an all-encompassing term. It covers processes and technologies for protecting files, databases, applications, user accounts, servers, network logins, and the network itself. But if you drill down a little in your thinking, it’s easy to see that data security is ultimately protecting a file somewhere on your system—whether desktops or servers. While data security is a good umbrella term, we need to get into more details to understand file security.
File Security and Permissions
As Microsoft reminds us, files (and folders or directories) are securable objects. They have access or permission rights for controlling who can read, write, delete, or execute at a very granular level through Access Control Lists (ACLs). And in Linux world, we have a similar, although far less granular, system of permissioning.
Get the Free Pen Testing Active Directory Environments EBook
Why have the concept of permissions in the first place?
Think of an enterprise computing environment as a semi-public place – you’re sharing a data space with not just anyone, but other employees. So a file is not the equivalent of box with a lock preventing anyone from accessing who doesn’t have a combination or key. Well, there is encryption, but we’ll cover that below. Instead the assumption in a Windows or Linux or other operating system environment is that you want to share resources.
The operating systems file system permission are there to provide a broad way to limit what can be done. For example, I want workers in another group to read our presentations, but I certainly don’t want them to edit. In that case, we’d specify — to be shown below — read and write permission for users who belong to group, and just read permission for everyone else.
In the Beginning, There Was Unix-Linux Permissions
Let’s look at a very simple permissioning system. It’s the classic Unix-Linux model, which provides basic read-write-execute permissions and a very simple method of deciding who these permissions apply to. It’s called the user-group-other model. Effectively, it divides the user community into three classes: the owner of the file (user), all those users belonging to groups that the owner is a member of (group), and finally everyone else (other). You can see this permission structure when you run an ls –l command:
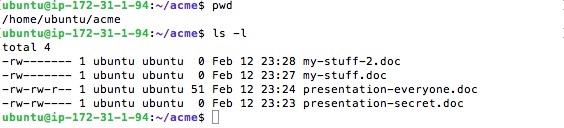
How do you specify a permission to add or subtract from a user-group-other? There’s the Linux chmod command. Suppose I decided that I’d like other users in groups I belong to have access to my-stuff-2. doc file, which I had been keeping private. I could do this:
chmod g+r my-stuff-2.doc
Or now I want to take back and make private the presentation-secret.doc file, which I had allowed other groups to view and update:
chmod g-rw presentation-secret.doc
The Unix-Linux permission model is simple and well-suited for server security, where there are system-level applications accessed by a few privileged users. It is not meant for a general user environment. For that you’ll need ACLs.
What Are Access Control Lists?
Windows has a far more complex permissioning system than Linux. It allows users to define a permission for any Active Directory user or group, which is represented internally by an unique number known as a SID (security identifier). Windows ACLs consist of a SID and another number representing the associated permission — read, write, execute, and more. This is called an access mask. The SID and the mask together are referred to as an access control entry or ACE.
We’ve all seen the user-friendly representation of the ACE when we view a file or folder’s properties:
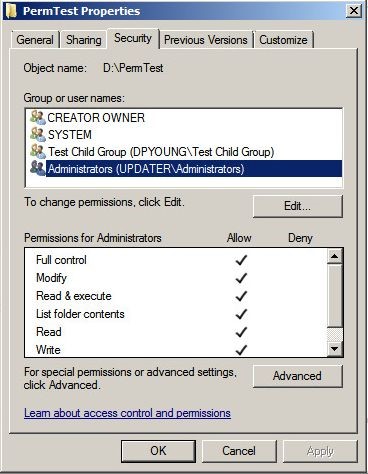
Obviously, ACLs can make permissioning quite complex. In theory, you can have ACEs for each user that needs to access a file or folder. No, you shouldn’t do that! Instead, there’s the preferred method of assigning users to a group and then combining all those groups that need access to a folder into a larger group. This umbrella group is then used in the ACL. I’ve just described something called AGLP for Account, Global, Local Permissioning, which is Windows approved method for efficient file and folder permissioning.
So if an employee moves to another project (or leaves the company) and therefore no longer needs access, you simply remove that user from the Active Directory group without having to adjust the ACE in the specific folder or file.
Easy peasy in terms of file security management. And a sensible way to reduce security risks in an enterprise computing environment.
And Along Came File Encryption
If you’re paranoid, there is encryption, which is certainly a valid, if extreme technique, for solving the issues of file security. It may be safe, but certainly a very impractical solution to securing file data. Windows supports encryption, and you can turn it on selectively for folders.
Technically, Windows use both asymmetric and symmetric encryption. The asymmetric part decrypts the symmetric key that does the actual block encryption/decryption of the file. The user has access to the private part of the asymmetric key pair that gets the whole process started. And only the owner of the folder can see the unencrypted files.
Obviously, with one user in control of the encryption, this does not lend itself to allowing multiple users to share access to files and folders. Add on that the potential for losing access to the asymmetric encryption key, which is kept in a certificate, and you can have a self-made ransomware attack on your hands. And yes, you should backup encryption certificates!
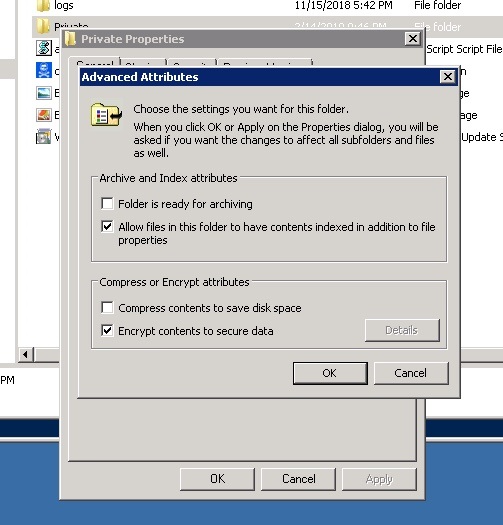
As we’ve been saying, the file system is where employees keep and share the content (spreadsheets, documents, presentations) that they’re working on now. It’s their virtual desks, and adding a layer of encryption is liking moving things around and making their desk even sloppier — no one likes that! — as well as being administratively difficult to manage.
Pseudonymization: Selective File Encryption
And this brings us to pseudonymization.
It’s a GDPR-approved technique for encoding personal data in order to reduce some of the burdens of this law.
The idea is to replace personal identifiers with a random code. It’s the same idea behind writers using pseudonyms to hide their identities. The GDPR says you can do this on a larger scale as a way to lessen some of the GDPR requirements.
Generally, there would have to be an intake system that would process the raw data identifiers and convert them to these special codes. And there would have to be a master table that maps the codes back into the real identifiers for those processes that need the original information.
Using this approach, employees could then work with pseudonymized files in which the identities of the data subjects would be hidden. The rest of the file, of course, would be readable.
Partial encryption is perhaps one way to think about this technique.
Like encryption, pseudonymization is considered a security protection measure (see the GDPR’s article 32), and it’s also explicitly mentioned as a “data by protection by design and by default” or PbD technique (see article 25). It’s also considered a personal data minimization technique — very important to the GDPR.
Will pseudonymization spread beyond the EU’s GDPR and be adopted by the US in its own coming data privacy and security law? We will see!
Best File Security Practices
Enterprise computing environments are designed to help employees get their work done. Sure there are built-from-the-ground-up secure operating systems, but they’re meant for top-secret government projects (or whatever Apple is working on next). For the rest of us, we have to learn to work with existing commercial operating systems, and find ways to minimize the risks of data security lapses.
Here are three easy-to-implement tips for boosting your file system security.
- Eliminate Everyone – The default Everyone group in Windows gives global access to a folder or file. You would think that companies would make sure to remove this group from a folder’s ACL. But in our most recent annual Data Risk Report, we’ve discovered that 58% of companies we sampled had over 100,00 folders open to every employee! Sure you’ll need to grant Everyone if you’re sharing the folder over the network, but make sure to remove from it from ACL and then do the following RBAC analysis .
- Roll Your Own Role-based Access Controls (RBAC) – Everyone has a job or role in an organization, and each role has with it an associated set of access permissions to resources. Naturally, you assign similar roles to the same group, and then apply to them the appropriate permissions, and then follow AGLP method from above. When implemented correctly, this should be easy to maintain while reducing security risks. Yes, this does require more than a little administrative overhead to maintain.
- Minimal Least Privilege Permission – This is related to RBAC, but it involves focusing particularly on “appropriate” permission. With the least privilege model, you pare down access to the minimum that is needed for the role. Marketing may need read access to a folder controlled by the finance department, but they shouldn’t be allowed to update a file or perhaps run some special financial software. Administrators need to be ruthlessly stingy when granting permissions with this approach.
I lied. These tips are super-easy to understand, but not super-easy to implement! You’ll need some help …
We just happen to have a solution that will make these great tips easier to put into practice.








