
データのディスカバリーと分類は、セキュリティ、コンプライアンス、安全なAI導入の基盤となります。最小権限、効果的なDLP、Microsoft Copilotなどのツールの安全な使用といった成果を達成するには、正確でスケーラブルな自動化された分類が必要です。AIの急速な流入により、リスクはさらに高まっています。AIはデータ量の爆発的な増加をもたらし、悪意のあるアクターに機密データを見つけ出して持ち出す新たな方法を提供します。
データ分類は、その重要性にもかかわらず、ほとんどの組織にとって依然として根強い課題です。「機密データはどこにあるのか」「どのような機密データがあるのか」といった単純な質問に答えるのも容易ではありません。
効果的なデータのディスカバリーと分類に対する万能な解決策はありません。従来のアプローチをそのまま活用したり、最新のテクノロジートレンドを追いかけたりすることはできません。セキュリティ、コンプライアンス、安全なAI導入のための効果的な基盤を構築するには、適切なツールが必要です。
このブログでは、データディスカバリーと分類へのアプローチ、そして正確さと規模に適した組み合わせを見つける方法について詳しく説明します。
データディスカバリーと分類における一般的な落とし穴
データのディスカバリーと分類のプロジェクトのほとんどは失敗するか、まったく立ち上がらないままです。一つの技術に過度に集中し、規模を拡大するために近道を取っていますが、最終的に、こうしたアプローチはデータセキュリティの基盤を脆弱にし、重要なデータを危険にさらします。これらの一般的な落とし穴を見てみましょう。
従来の正規表現のみのアプローチ
一部のベンダーは分類を正規表現(regex)のみに依存しています。このアプローチは、予測可能なパターンを見つけるのに効果的でスケーラブルである一方、曖昧さ、文脈、新しいデータタイプには苦労します。さらに、これらのルールは新しいデータタイプに対応するために専門チームによる手動調整を必要とすることが多く、セキュリティチームは永続的なポリシー管理と誤検知に悩まされています。
AI専用の罠
大規模言語モデル(LLM)とその文脈や意味を理解する能力については、多くの話題が飛び交っています。LLMは新しいデータ型を効果的に分類できますが、分類をAIだけに頼るのは危険です。これらのモデルは、正確な結果を提供し、推測やハルシネーションによるエラーを避けるために、業界や企業に特化した適切に管理されたトレーニングデータを必要とします。
ベンダーが適切に訓練されたモデルを使用せずにデータを分類すると、出力は信頼性を欠き、規模に応じてコストが急速に増加する可能性があります。簡単に言えば、AIは、データのディスカバリーと分類の大部分を占める、よく知られたパターンの決定論的かつ高精度な識別に対しては効率的ではありません。話題にはなっていますが、目標は単なる「AI」導入ではなく、正確性と効率性であることを念頭に置くことが重要です。
サンプリングのショートカット
ベンダーの主なセールスポイントがスキャン速度である場合、それは多くの場合、アーキテクチャの近道であるサンプリングを意味します。大規模なデータ資産全体で迅速な結果を得るために、一部のプラットフォームは、フルスキャンのリソース要求を回避し、代わりにデータのサブセットのみを分析します。これは一度限りのスナップショットとしては許容されるかもしれませんが、継続的なセキュリティプログラムの基盤としては不安定です。
サンプリングは設計上、盲点を生み出し、監査レベルのコンプライアンスを維持し、正確なポリシーを施行し、違反に効果的に対応することを不可能にします。
真の目標は、信頼できる分類の実現です。データのディスカバリーと分類は、データの完全で継続的に更新され、スケーラブルなコンテキストビューを提供する必要があります。
解決策:適材適所のツール
ネジを打ち込むのにハンマーを使わないのと同じように、すべてのデータ型に単一の分類方法を使用すべきではありません。スケーラブルなアプローチは、複数の分野の最良の要素を組み合わせます。
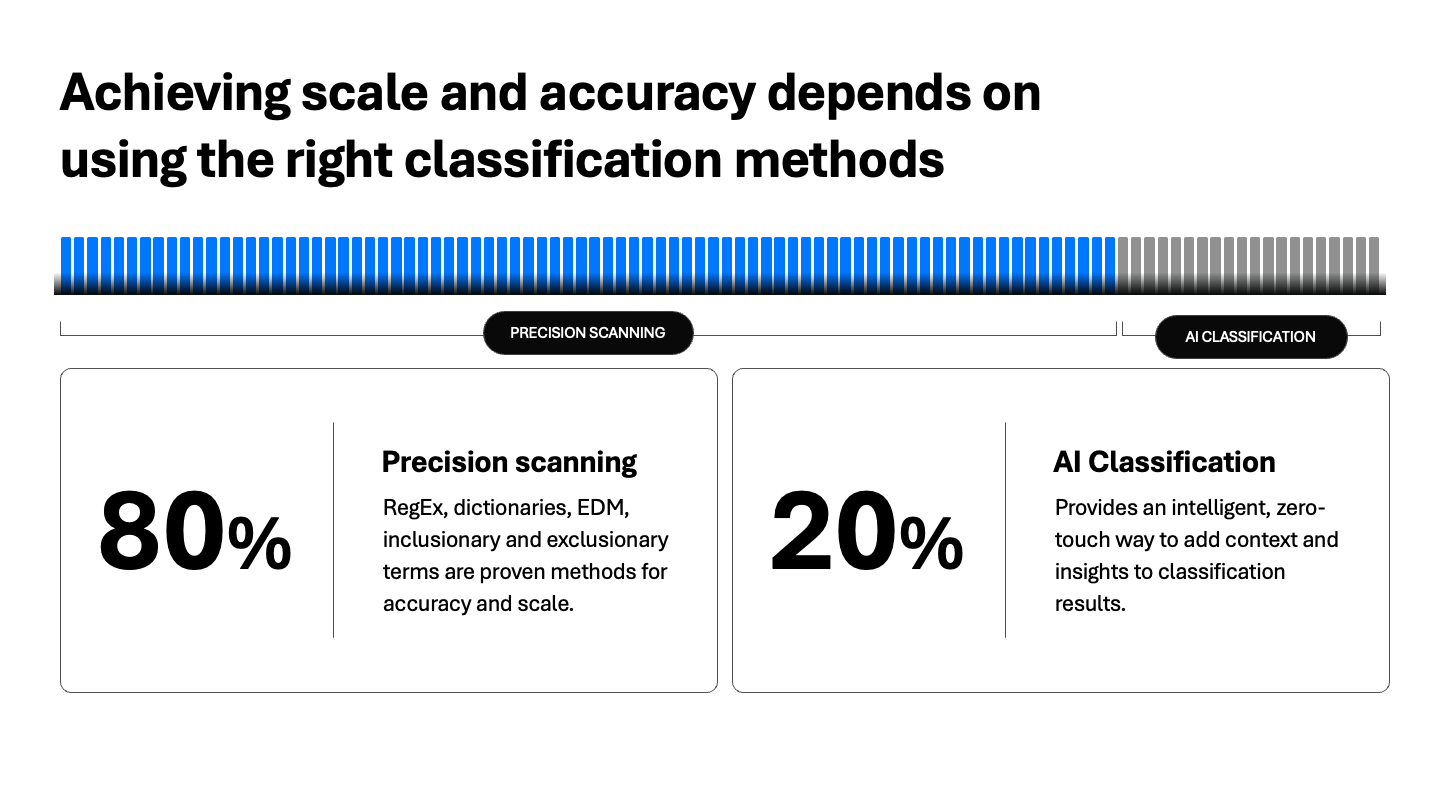
- パターンベースの分類:パターンベースの分類は、クレジットカード番号や医療識別子などの構造化データタイプにおいて最も重要です。近接マッチング、除外キーワード、アルゴリズム検証(例:クレジットカードのLuhn)などの技術は、低い計算コストで高精度を提供します。
- 完全データ一致(EDM):レコードレベルの確実性が求められる場合(例:マスターEMRシステムの患者ID22814)、EDMは不可欠です。非構造化データをハッシュ化された参照セットと比較し、誤検出をほぼゼロに抑え、重要なデータを正確に検証します。
- AI/LLMを活用した分類:AIはあいまいさがあるときに有用です。これは、新しいデータタイプを分類したり、一貫性のないスキーマを解釈したり、分類結果に文脈を追加したりするための強力なツールです。パターンロジックを重ね合わせたAIは、特に曖昧なデータや進化するデータに対して、全体的な精度と実用性を高めます。
規模と精度を達成するには、適切な分類方法を使用する必要があります。
要点:最速で最も正確な方法(パターン)を最初に使用し、絶対的な確実性を得るためにEDMを導入し、深い文脈理解のためにAIを重ねます。
データのディスカバリーと分類への実用的なアプローチ
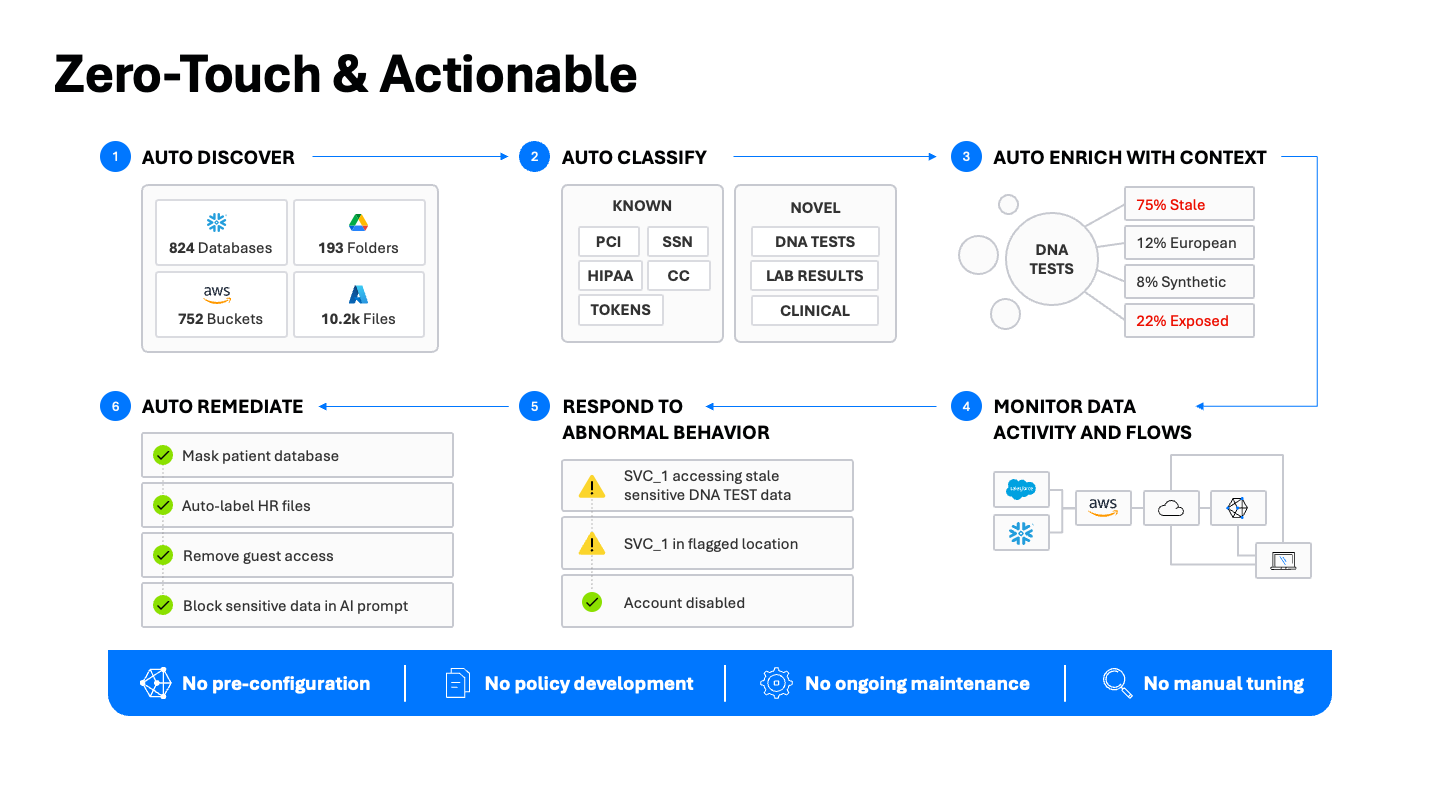
データのディスカバリーと分類においては、可視性だけではなく、データの保護が重要となります。Varonisデータセキュリティプラットフォームは、発見から修正まで、データセキュリティに対するエンドツーエンドのアプローチを提供し、手作業を削減し、各段階でセキュリティ成果を加速するように設計されています。
- データストアの自動検出:クラウド、SaaS、ハイブリッドを含むシステム全体のデータを自動的にマッピングします。何百ものデータベース、何千ものバケット、無数のファイル共有が、すべて継続的にインベントリされています。
- 最適なツールで自動分類:包括的なフルスキャンから始め、基準を確立し、パターンマッチング、完全データ一致(EDM)、AI支援分類を組み合わせて精度を確保します。次に、増分スキャンで効率的に拡張し、ネイティブのアクティビティログを活用して変更を検出し、新しいものや変更されたものだけをスキャンします。
- 文脈の充実化:データ型を超えて、主題、トピック、適用される規制を充実させます。例えば、あるファイルは単に「PIIを含む」だけでなく、「HIPAA規制データを含む患者受付フォーム」が含まれるとすべきです。その文脈は、実用的なデータセキュリティを提供するために重要です。
- データの活動とフローを監視:データ、ID、ネットワーク、機密性のテレメトリを相互に関連付ける統一された監査証跡を維持し、機密データがどのように使用され、どこに移動し、誰によって使用されているかを確認します。これにはAIプロンプトのやり取りも含まれます。
- 異常な振る舞いに対応:正確な分類がDLPを強化し、リスクモデリングを可能にすることで、UEBAは複雑な敵対者の行動を浮き彫りにします。分類コンテキストでアラートを強化し、データの流出、内部脅威、AIツールの悪用を検出します。Varonis 24x7 MDDRを使用すると、爆発範囲と信頼性に基づいてアラートを優先順位付けし、調査を迅速化できます。
- 自動修復:分類結果は、セキュリティの改善に直接反映される必要があります。ここで自動修正機能が役立ちます。機密データを自動的にマスクし、人事ファイルに自動ラベルを付け、危険なゲストアクセスを削除し、機密データがAIプロンプトに入力されないようにし、不要なサービスチケットや複雑な統合を作成することなく実現します。
私たちの運営原則は確固たるものです:事前設定、継続的なポリシーメンテナンス、手動チューニングは一切ありません。迅速で簡単な導入と即時の価値提供のみです。
安全な展開とデータのレジデンシー
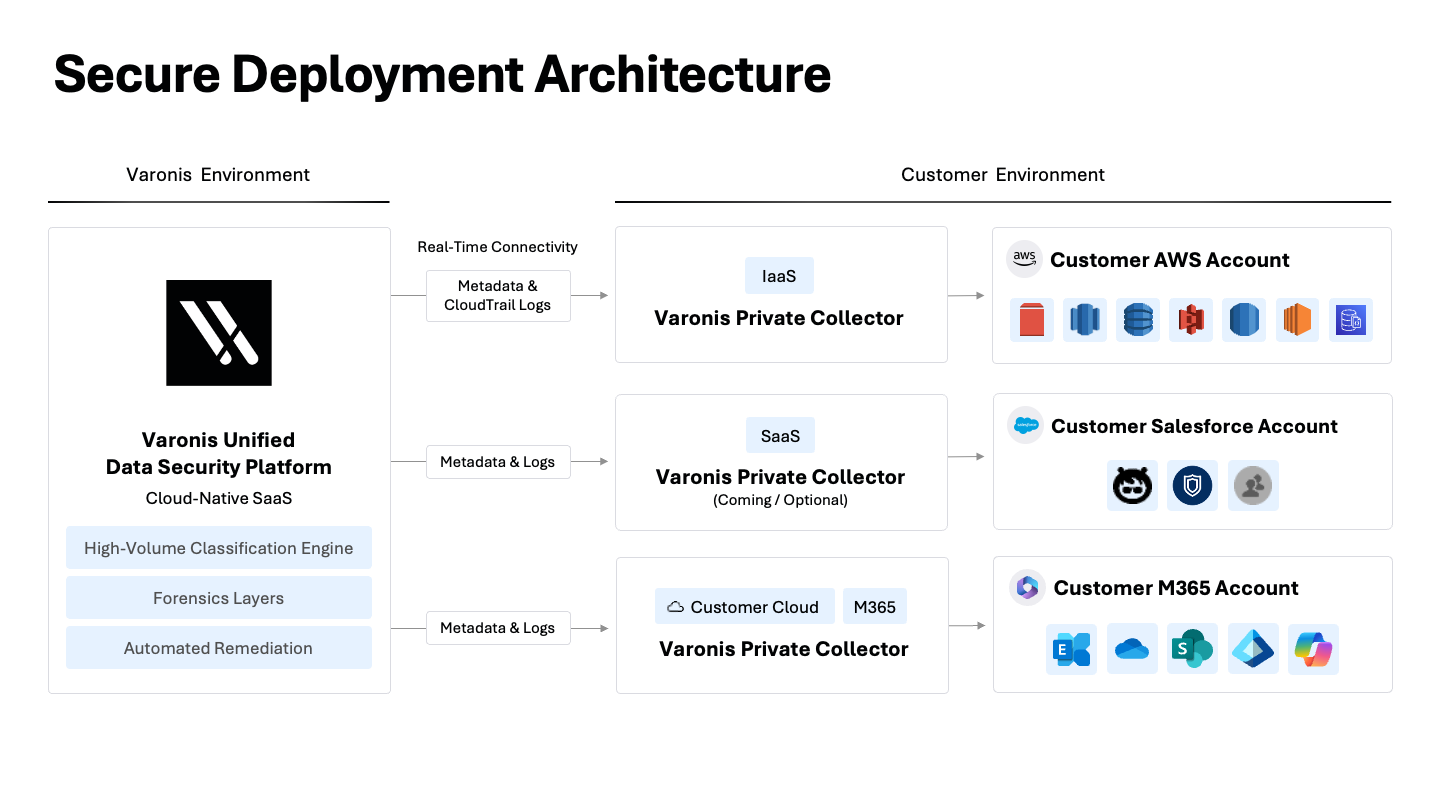
データがどのようにスキャンされるかが重要です。スケールに対応するために、多くのベンダーはデータサンプルを自社のクラウドに直接転送して分類します。これにより、プライバシーのリスクが生じ、攻撃対象領域が拡大し、データの制御が奪われます。データのレジデンシーが問題となる場合、直接のデータ転送は避けるべきです。
Varonisのアプローチには、堅牢なテナント分離、データレジデンシー要件を満たすリージョン内処理、転送中と保存中の暗号化が含まれます。他のベンダーとは異なり、当社のAIモデルのトレーニングに顧客データが使用されることは決してありません。
厳格なデータ保存規則を持つ組織の場合、当社のデータコレクターアーキテクチャを使用すると、環境を離れることなくデータを処理および分類できます。
当社のセキュリティ対策、コンプライアンス認証、プライバシーポリシーについて詳しく知りたい場合は、Varonis Trust Centerをご覧ください。
分類から制御へ:現実世界での成果
自動化されたデータ分類は、可視性だけではなく、重要なセキュリティ成果を実現します。ここで現実世界での事例をご紹介します。
ユースケース:タンパ総合病院がAIを安全に導入
課題:Microsoft 365 Copilotを10,000人の臨床およびバックオフィススタッフに、機密性の高い患者データ(PHI)が露出するリスクを冒すことなく展開すること。
解決策:
- リスクを発見:PHIを含む数百万のファイルが危険なほど過剰に露出されていることを自動的に発見し、分類しました。
- 問題を解決:AIが導入される前に患者データをロックし、数日で権限を最小権限モデルに修正しました。
- データリスクに関するアラート:すべてのデータアクティビティを継続的に監視し、導入後にAIプロンプトが異常なアクセスや危険な共有をリアルタイムで検出して停止します。
結果:タンパ総合病院はAIアシスタントを組織全体に自信を持って成功裏に導入し、最も機密性の高いデータをHIPAAに準拠した状態で安全に保ちながら、イノベーションを実現しました。
ユースケース:米国最大の信用組合の1つがエンタープライズDLPを導入
課題:
DLPコントロールを導入し、会員の個人識別情報(PII)と支払いカードデータを内部および外部の脅威から保護しつつ、規制遵守を確保します。
解決策:
- リスクを発見:PIIおよびPCIデータを含む数百万のファイルを検出して分類し、正確なDLPと広範囲にわたるオープンアクセスの発見のための基盤を提供しました。
- 問題を解決:自動化された最小権限の修復によりオープンアクセスを93%削減し、許可されたユーザーのみがアクセスを保持できるようにします。
- データリスクに関するアラート:データアクティビティをリアルタイムで監視し、3つの別々のインシデントを調査するためにVaronisインシデントレスポンスチームを関与させました。
結果:同信用組合は自信を持ってDLPを導入し、機密性の高い会員データの安全性を確保しながら、侵害のリスクを軽減し、CCPAなどの規制に準拠することができました。
その公式はシンプルです。正確な分類を使用して危険にさらされているものを見つけ、露出しているものを修正し、疑わしいアクティビティを警告します。
分類が安全なAIとダウンストリーム制御を可能にする仕組み
データの発見と分類は、Microsoft 365 Copilot、ChatGPT Enterprise、Salesforce Agentforce などの AI アシスタントを安全に活用するために不可欠です。知らないものは保護できません。機密データを特定することは、適切な制御を適用し、AI がそれを露出するのを防ぐために重要です。
しかし、その影響はAIをはるかに超えて広がります。正確な分類により、最も重要なダウンストリームの制御が強化されます。脅威の検出と対応に高忠実度の文脈が追加され、効果的なDLPが実現し、インサイダーリスクプログラムが強化され、データライフサイクルの自動化が可能になります。
グラウンドトゥルース分類は、適切なガードレールを構築するための方法です。機密データがどこに移動されても、どのAIエージェントが展開されても、機密データが漏洩や悪用から確実に保護されるようにします。
成果をもたらす分類を確認する準備はできていますか?
ポリシーの管理をやめて、リスクの管理を始めましょう。
無料のデータリスクアセスメントを実行して、データの完全かつ最新のコンテキストビューを取得し、AIガードレールとDLPの明確な次のステップを把握しましょう。
