
El descubrimiento y la clasificación de datos son la base para la seguridad, el cumplimiento y la adopción segura de la IA. Para lograr objetivos como privilegios mínimos, un DLP efectivo y el uso seguro de herramientas como Microsoft Copilot, es fundamental contar con una clasificación de datos precisa, escalable y automatizada. Con la rápida llegada de la IA, los riesgos son aún mayores. La IA lleva a una explosión en los volúmenes de datos y ofrece a los actores malintencionados nuevas formas de encontrar y exfiltrar datos confidenciales.
A pesar de la importancia de la clasificación de datos, sigue siendo un desafío constante para la mayoría de las organizaciones. Tienen dificultades para responder preguntas simples como “¿Dónde están mis datos confidenciales?” y “¿Qué tipo de datos confidenciales tengo?”.
No hay una solución mágica para el descubrimiento y la clasificación efectivos de datos. No puede simplemente aprovechar los enfoques tradicionales o seguir la última tendencia tecnológica. Para construir una base efectiva para la seguridad, el cumplimiento y la adopción segura de la IA, necesita la herramienta adecuada para el trabajo.
En este blog, detallaremos los enfoques para el descubrimiento y la clasificación de datos y cómo encontrar la combinación correcta para la precisión y la escala.
Errores comunes en el descubrimiento y clasificación de datos
La mayoría de los proyectos de descubrimiento y clasificación de datos fracasan o nunca llegan a despegar. Se centran demasiado en una técnica y toman atajos para lograr la escala. Estos enfoques terminan creando una base deficiente para la seguridad de los datos, lo que pone en riesgo la información crítica. Echemos un vistazo a estos errores comunes.
El enfoque tradicional que solo utiliza expresiones regulares
Algunos proveedores dependen exclusivamente de expresiones regulares (regex) para la clasificación. Aunque es efectivo y escalable para encontrar patrones previsibles, este enfoque tiene dificultades con la ambigüedad, el contexto y los tipos de datos nuevos. Además, estas reglas suelen requerir un ajuste manual por parte de equipos especializados para mantenerse al día con los nuevos tipos de datos, lo que entierra a los equipos de seguridad en una gestión perpetua de políticas y falsos positivos.
La trampa de solo usar IA
Hay mucho revuelo en torno a los modelos de lenguaje de gran tamaño (LLM) y su capacidad para comprender el contexto y la semántica. Aunque los LLM pueden clasificar tipos de datos novedosos de manera efectiva, es arriesgado confiar únicamente en la IA para la clasificación. Estos modelos requieren datos de entrenamiento bien seleccionados, a menudo específicos de la industria o de la empresa, para proporcionar resultados precisos y evitar errores por conjeturas o alucinaciones.
Si un proveedor clasifica datos sin un modelo entrenado de forma adecuada, el resultado no es confiable y puede aumentar rápidamente los costos a escala. En pocas palabras, la IA no es eficiente para la identificación precisa y determinista de patrones ya conocidos, que es lo que constituye la mayor parte del proceso de descubrimiento y clasificación de datos. A pesar del revuelo, es esencial recordar que el objetivo es la precisión y la eficiencia, no solo la “IA”.
El atajo de muestreo
Cuando el principal argumento de venta de un proveedor es la velocidad de escaneo, a menudo indica que hay un atajo de arquitectura: el muestreo. Para obtener resultados rápidos en grandes volúmenes de datos, algunas plataformas evitan las exigencias de recursos de los escaneos completos y analizan solo un subconjunto de los datos. Aunque eso podría ser aceptable para una instantánea puntual, crea una base inestable para cualquier programa de seguridad continuo.
El muestreo crea puntos ciegos por diseño, lo que hace imposible mantener un cumplimiento auditable, aplicar políticas precisas y responder de manera efectiva ante una vulneración.
El verdadero objetivo es una clasificación en la que pueda confiar. El descubrimiento y la clasificación de datos deben proporcionar una vista contextual completa y continuamente actualizada de sus datos que sea escalable.
La solución: la herramienta adecuada para el trabajo adecuado
Así como no usaría un martillo para colocar un tornillo, tampoco debería usar un solo método de clasificación para cada tipo de dato. Un enfoque escalable combina lo mejor de varios mundos:
- Clasificación basada en patrones: la clasificación basada en patrones es primordial para los tipos de datos estructurados, como números de tarjetas de crédito o identificadores de atención médica. Técnicas como la coincidencia de proximidad, las palabras clave negativas y la verificación algorítmica (p. ej., Luhn para tarjetas de crédito) ofrecen alta precisión a bajo costo computacional.
- Coincidencia exacta de datos (EDM): cuando se requiere certeza a nivel de registro (p. ej., esta es la identificación del paciente 22814 de nuestro sistema principal de EMR), la EDM es indispensable. Compara datos no estructurados con un conjunto de referencia cifrado, lo que genera casi cero falsos positivos y verifica datos críticos con precisión.
- Clasificación asistida por IA/LLM: la IA se destaca cuando hay ambigüedad. Es una herramienta poderosa para categorizar tipos de datos novedosos, interpretar esquemas inconsistentes o agregar contexto a los resultados de clasificación. Con lógica de patrones en capas, la IA incrementa la precisión y la capacidad de acción en general, en especial, para datos ambiguos o en evolución.
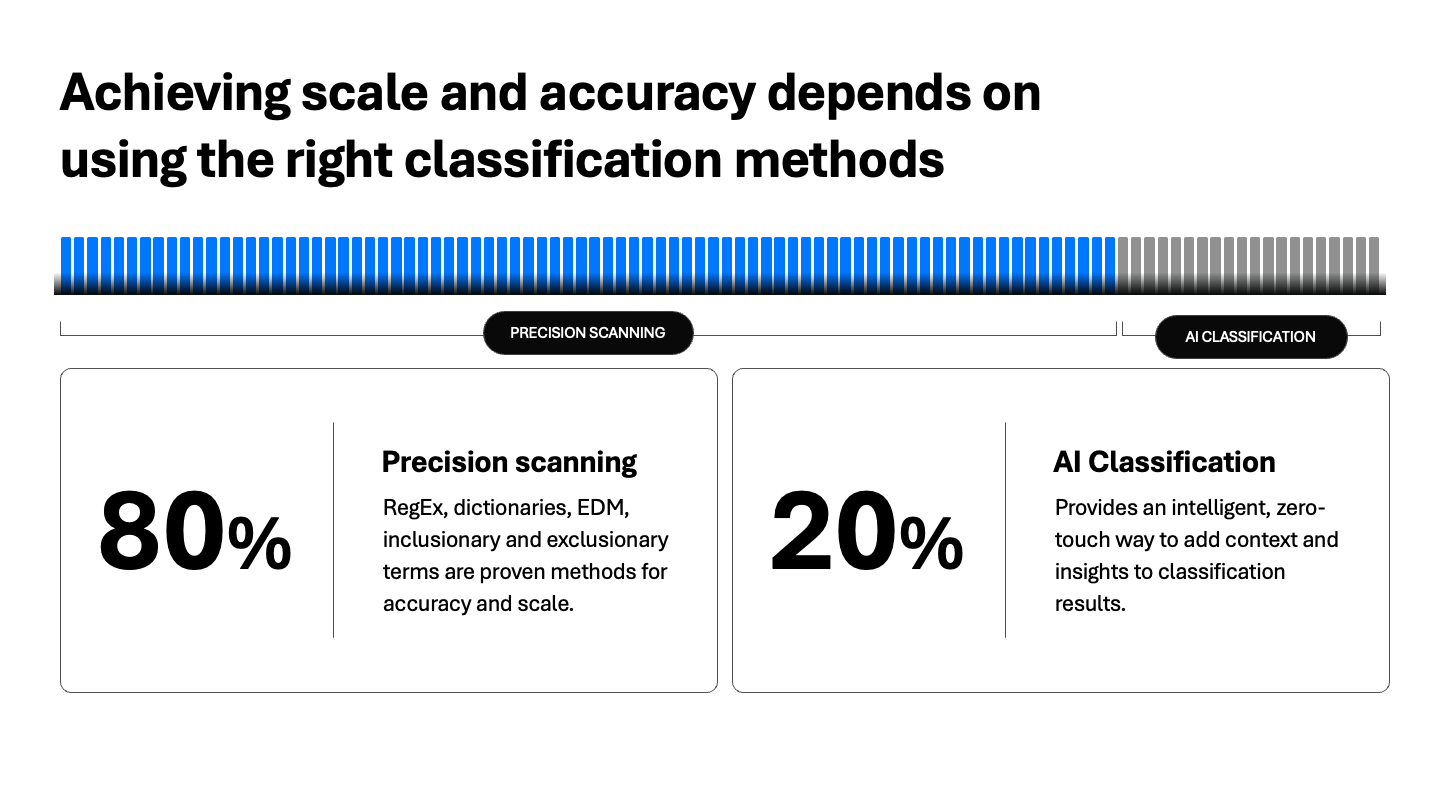
Lograr escala y precisión depende del uso de los métodos de clasificación apropiados
Conclusión: use el método más rápido y preciso primero (patrones), incorpore EDM para tener certeza absoluta y agregue IA para una comprensión profunda del contexto.
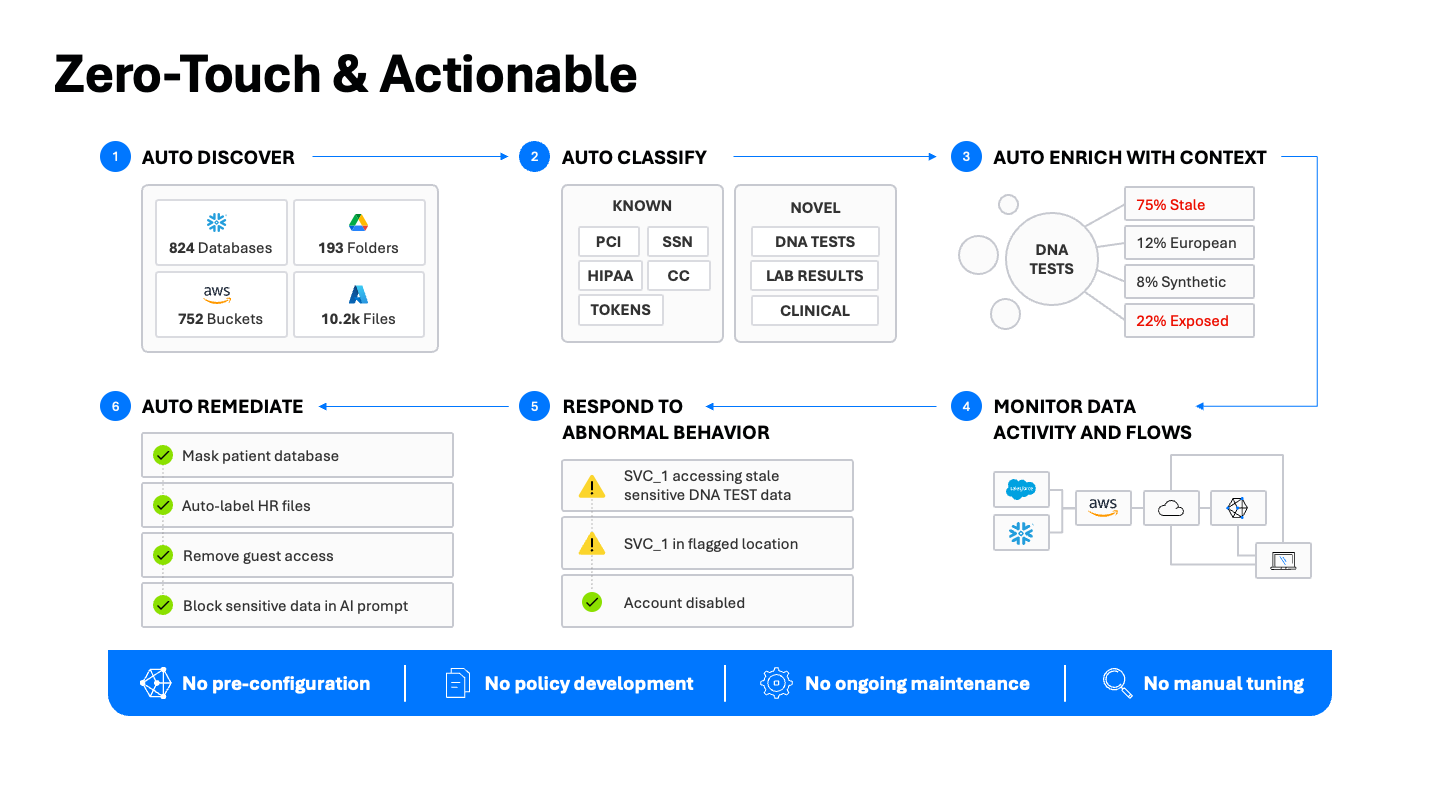
Un enfoque práctico para el descubrimiento y clasificación de datos
El descubrimiento y la clasificación de datos no se tratan solo de visibilidad. Se tratan de proteger los datos. La Plataforma de seguridad de datos Varonis ofrece un enfoque integral para la seguridad de los datos, desde el descubrimiento hasta la remediacion, con un diseño para reducir el esfuerzo manual y acelerar los resultados de seguridad en cada paso.
- Descubrimiento automático de repositorios de datos: mapee los datos de manera automática en toda su infraestructura, lo que incluye entornos de nube, SaaS e híbridos. Cientos de bases de datos, miles de buckets e innumerables recursos compartidos de archivos, todos inventariados continuamente.
- Clasificación automática con la mejor herramienta: comience con un escaneo completo para establecer una línea de base, utilizando una combinación de coincidencia de patrones, coincidencia exacta de datos (EDM) y clasificación asistida por IA para garantizar la precisión. Luego escale eficientemente con el escaneo incremental, al aprovechar los logs de actividad nativos para detectar cambios y escanear solo lo que es nuevo o se ha modificado.
- Enriquecimiento con contexto: vaya más allá del tipo de datos para enriquecer con el tema, el asunto y las regulaciones aplicables. Un archivo no solo “contiene información personal identificable”. Contiene un “formulario de admisión de pacientes que contiene datos regulados por la HIPAA”. Ese contexto es fundamental para informar sobre la seguridad de los datos de manera procesable.
- Monitoreo de la actividad y los flujos de datos: mantenga una trazabilidad de auditoría que correlacione la telemetría de datos, identidad, red y sensibilidad para ver cómo se utilizan los datos clasificados, por dónde se mueven y quién los utiliza, incluidas las interacciones de las indicaciones de IA.
- Respuesta a un comportamiento anormal: la clasificación precisa potencia el DLP y el modelado de riesgos, lo que permite a UEBA identificar comportamientos complejos de adversarios. Enriquezca las alertas con contexto de clasificación para detectar exfiltraciones, amenazas internas y uso indebido de herramientas de IA. Priorice las alertas por radio de ataque potencial y confianza y acelere las investigaciones con la MDDR de Varonis las 24 horas del día, los 7 días a la semana.
- Remediación automática: los resultados de la clasificación deben traducirse directamente en mejoras de seguridad. Aquí es donde entra la remediacion automatizada. Enmascare automáticamente los datos confidenciales, etiquete automáticamente los archivos de RR. HH., elimine el acceso de invitados de alto riesgo y evite que los datos confidenciales entren en las indicaciones de IA, todo ello sin crear tickets de servicio innecesarios o integraciones complejas.
Nuestro principio operativo es firme: no hay preconfiguración, no hay mantenimiento continuo de políticas ni ajuste manual, solo una implementación rápida, fácil y de valor inmediato.
Implementación segura y residencia de datos
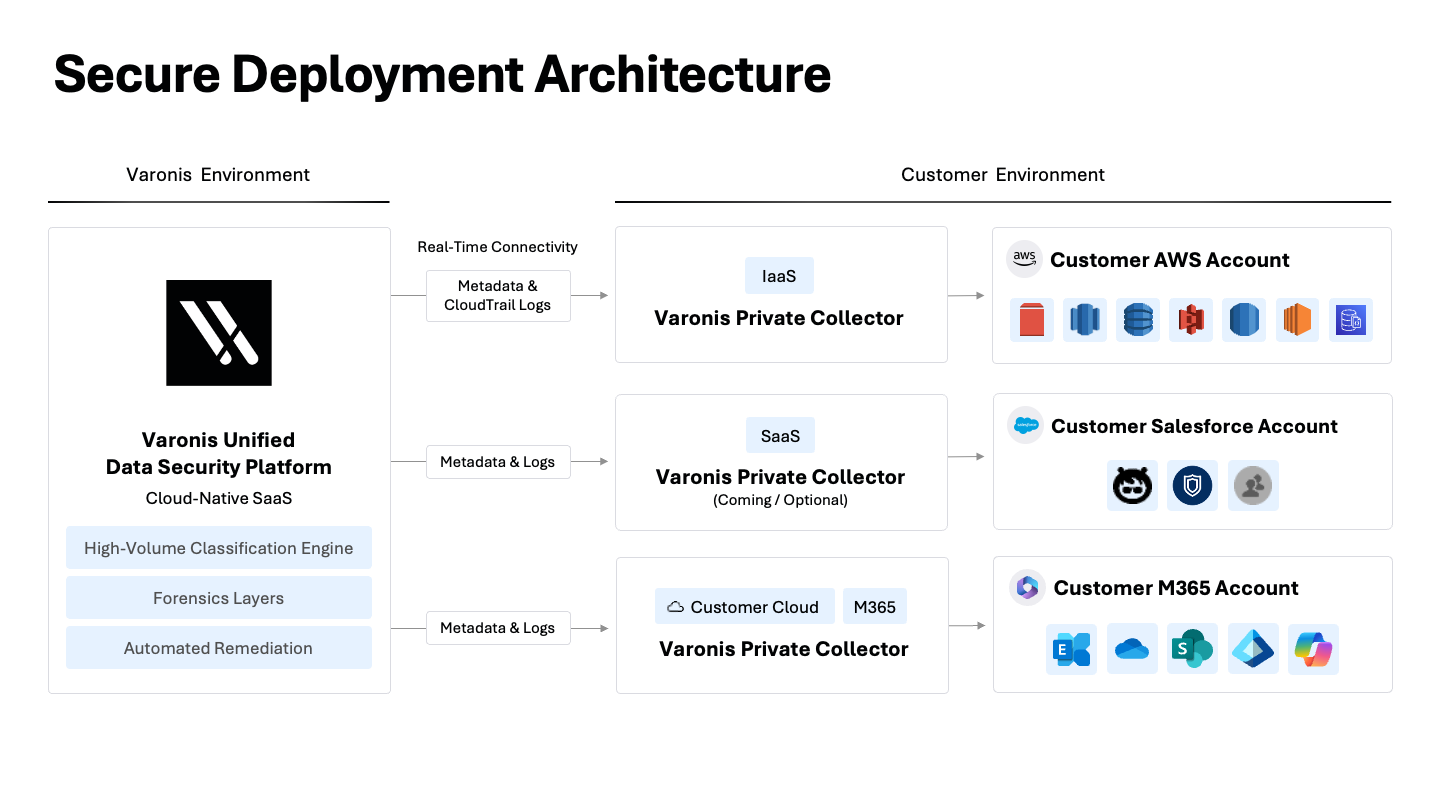
La manera en que se escanean sus datos importa. Para ayudar con la escala, muchos proveedores transfieren sus muestras de datos directamente a su nube para clasificarlas. Esto crea un riesgo de privacidad, aumenta su superficie de ataque y le quita el control de sus datos. Si la residencia de los datos es una preocupación, la transferencia directa de datos no debería ser una opción.
El enfoque de Varonis incluye un sólido aislamiento del tenant, procesamiento dentro de la región para cumplir con los requisitos de residencia de datos y cifrado en tránsito y en reposo. A diferencia de otros proveedores, los datos de los clientes nunca se utilizan para entrenar nuestros modelos de IA.
Para las organizaciones con reglas estrictas de residencia de datos, nuestra arquitectura de recopilación de datos les permite procesar y clasificar datos sin que estos salgan de su entorno.
Para obtener más información sobre nuestras prácticas de seguridad, certificaciones de cumplimiento y políticas de privacidad, le recomendamos visitar el Centro de confianza de Varonis.
De la clasificación al control: resultados reales
La clasificación automatizada de datos proporciona más que solo visibilidad; habilita resultados críticos de seguridad. Así es como se ve en el mundo real:
Caso de uso: Tampa General Hospital despliega IA de forma segura
Desafío: desplegar Microsoft 365 Copilot para 10 000 empleados clínicos y administrativos sin arriesgar la exposición de datos confidenciales de los pacientes (PHI).
Solución:
- Encontrar el riesgo: se descubrieron y clasificaron automáticamente millones de archivos que contenían PHI que estaban peligrosamente sobreexpuestos.
- Solucionar el problema: se remediaron los permisos a un modelo de mínimo privilegio en pocos días, lo que protegió los datos de los pacientes antes de que se implementara la IA.
- Alertar sobre el riesgo de datos: monitoree continuamente toda la actividad de datos y las indicaciones de IA después de la implementación para detectar y detener el acceso anormal o el intercambio riesgoso en tiempo real.
Resultado: Tampa General implementó con éxito y confianza asistentes de IA en toda la organización, lo que hizo posible la innovación mientras se garantizaba que sus datos más confidenciales permanecieran seguros y cumplieran con la HIPAA.
Caso de uso: una de las mayores cooperativas de crédito de EE. UU. implementa DLP empresarial
Desafío:
Implementar controles de DLP para proteger la PII de los miembros y los datos de tarjetas de pago, tanto de amenazas internas como externas, al mismo tiempo que se garantiza el cumplimiento de las normativas.
Solución:
- Encontrar el riesgo: se descubrieron y clasificaron millones de archivos con datos de PII y PCI, lo que proporciona la base para un DLP preciso y expone el acceso abierto generalizado.
- Solucionar el problema: reduzca el acceso abierto en un 93 % mediante la remediacion automatizada de privilegios mínimos, lo que garantiza que solo los usuarios autorizados conserven el acceso.
- Alertar sobre el riesgo de datos: se mantuvo la supervisión en tiempo real de la actividad de datos y se involucró al equipo de respuesta a incidentes de Varonis para investigar tres incidentes separados.
Resultado: la cooperativa de crédito desplegó DLP con confianza, lo que redujo el riesgo de vulneraciones al tiempo que garantizó que los datos confidenciales de los socios permanecieran seguros y cumplieran con normativas como la CCPA.
La fórmula es simple: use una clasificación precisa para encontrar lo que está en riesgo, corregir lo que está expuesto y alertar sobre actividades sospechosas.
Cómo la clasificación permite una IA segura y controles posteriores
El descubrimiento y la clasificación de datos son esenciales para aprovechar de forma segura los asistentes de IA como Microsoft 365 Copilot, ChatGPT Enterprise y Salesforce Agentforce. No se puede proteger lo que no se sabe. Identificar datos confidenciales es fundamental para aplicar los controles adecuados y evitar que la IA los exponga.
Pero su impacto se extiende mucho más allá de la IA. La clasificación precisa potencia sus controles posteriores más críticos: agrega contexto de alta fidelidad a la detección y respuesta a amenazas, permite un DLP eficaz, fortalece los programas de riesgo interno y hace posible la automatización del ciclo de vida de los datos.
La clasificación basada en datos reales es la forma de construir controles de seguridad adecuados. Garantiza que los datos confidenciales estén protegidos contra la exposición o el uso indebido, sin importar a dónde se trasladen o qué agentes de IA implemente.
¿Está listo para ver una clasificación que ofrece resultados?
Deje de gestionar políticas y empiece a gestionar el riesgo.
Ejecute una Evaluación de riesgo sobre los datos gratuita para obtener una visión completa, actual y contextual de sus datos, además de pasos claros para los controles de seguridad de IA y DLP.
Tenga en cuenta que este blog se tradujo con la ayuda de IA y un traductor humano lo revisó.








