
La découverte et la classification des données constituent le fondement de la sécurité, de la conformité et de l’adoption sécurisée de l’IA. Pour obtenir des résultats tels que le principe du moindre privilège, une protection efficace contre la fuite de données (DLP) et une utilisation sécurisée d’outils tels que Microsoft Copilot, il est nécessaire de disposer d’une classification précise, évolutive et automatisée. Avec l’arrivée rapide de l’IA, les enjeux sont encore plus importants. L’IA entraîne une explosion des volumes de données et offre aux acteurs malveillants de nouveaux moyens de trouver et d’exfiltrer des données sensibles.
Malgré l’importance de la classification des données, celle-ci reste un défi permanent pour la plupart des organisations. Ces dernières ont des difficultés à répondre à des questions simples telles que « où se trouvent mes données sensibles ? » et « de quel type de données sensibles est-ce que je dispose ? ».
Il n’existe pas de solution miracle pour une découverte et une classification efficaces des données. Vous ne pouvez pas simplement vous appuyer sur des approches traditionnelles ou suivre les dernières tendances technologiques. Pour établir une base efficace en matière de sécurité, de conformité et d’adoption sécurisée de l’IA, vous avez besoin de l’outil adapté à la tâche.
Dans cet article, nous allons détailler les approches en matière de découverte et de classification des données, ainsi que la manière de trouver la bonne combinaison pour garantir précision et évolutivité.
Pièges courants dans la découverte et la classification des données
La plupart des projets de découverte et de classification des données échouent ou ne voient jamais le jour. Ils se concentrent trop sur une seule technique et prennent des raccourcis pour atteindre leur objectif. Au final, ces approches aboutissent à une base insuffisante pour la sécurité des données, ce qui met en péril les données critiques. Examinons ces écueils courants.
L’approche traditionnelle basée uniquement sur les expressions régulières
Certains fournisseurs s’appuient exclusivement sur des expressions régulières (regex) pour la classification. Bien qu’efficace et évolutive pour détecter des schémas prévisibles, cette approche peine à gérer l’ambiguïté, le contexte et les nouveaux types de données. De plus, ces règles nécessitent souvent un ajustement manuel par des équipes spécialisées afin de s’adapter aux nouveaux types de données, ce qui oblige les équipes de sécurité à se consacrer en permanence à la gestion des politiques et aux faux positifs.
Le piège de l'IA uniquement
Les grands modèles de langage (LLM) et leur capacité à comprendre le contexte et la sémantique font beaucoup parler d’eux. Si les LLM peuvent classer efficacement de nouveaux types de données, il est risqué de s’appuyer uniquement sur l’IA pour la classification. Ces modèles nécessitent des données d’entraînement bien sélectionnées, souvent spécifiques à un secteur ou à une entreprise, afin de fournir des résultats précis et d’éviter les erreurs dues à des conjectures ou à des hallucinations.
Si un fournisseur classe les données sans disposer d’un modèle correctement formé, le résultat n’est pas fiable et peut rapidement faire grimper les coûts à grande échelle. En termes simples, l’IA n’est pas efficace pour l’identification déterministe et de haute précision de modèles bien connus, qui constituent l’essentiel de la découverte et de la classification des données. Malgré l’engouement qu’elle suscite, il est essentiel de garder à l’esprit que l’objectif est la précision et l’efficacité, et pas seulement « l’IA ».
Le raccourci d'échantillonnage
Lorsque le principal argument de vente d’un fournisseur est la vitesse d’analyse, cela indique souvent un raccourci architectural : l’échantillonnage. Pour obtenir des résultats rapides sur de grands ensembles de données, certaines plateformes évitent les exigences en ressources des analyses complètes et se contentent de traiter un sous-ensemble des données. Si cela peut être acceptable pour un instantané ponctuel, les bases ainsi posées sont peu solides pour un programme de sécurité continu.
L’échantillonnage crée des angles morts par nature, rendant impossible le maintien d’une conformité de niveau audit, l’application de politiques précises et la réponse efficace à une fuite.
Le véritable objectif est d’obtenir une classification fiable. La découverte et la classification des données doivent fournir une vue contextuelle complète, continuellement mise à jour et évolutive de vos données.
La solution : le bon outil pour le bon travail
Tout comme vous n'utiliseriez pas un marteau pour enfoncer une vis, vous ne devriez pas utiliser une seule méthode de classification pour chaque type de données. Une approche évolutive combine le meilleur de plusieurs mondes :
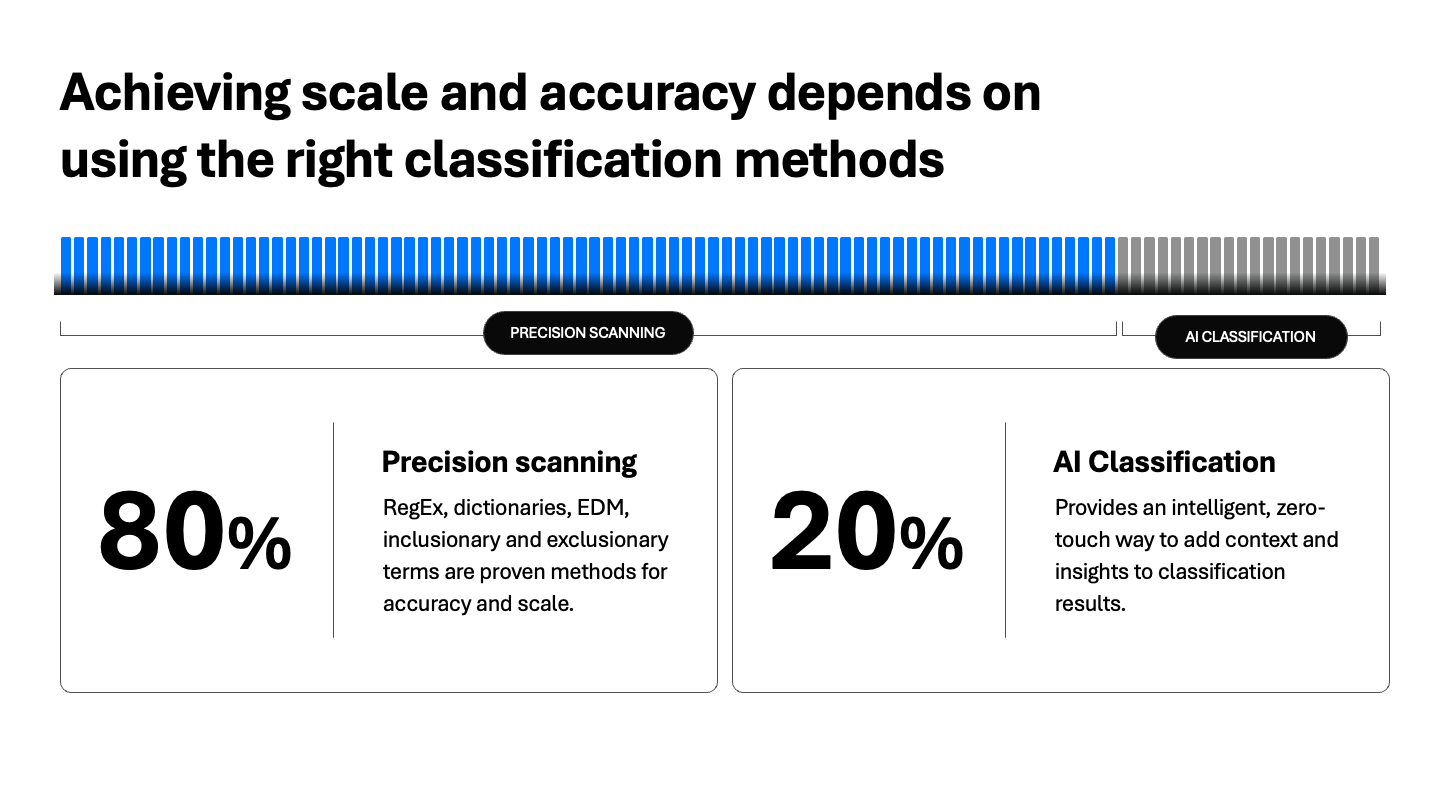
- Classification basée sur des modèles : La classification basée sur des modèles est idéale pour les types de données structurées telles que les numéros de carte bancaire ou les informations d’identification médicales. Des techniques telles que la correspondance de proximité, les mots-clés négatifs et la vérification algorithmique (par exemple, Luhn pour les cartes bancaires) offrent une grande précision à un faible coût informatique.
- Correspondance exacte des données (EDM) : Lorsque le niveau de certitude requis est maximal (par exemple, il s’agit du patient n° 22814 issu de notre système EMR principal), l’EDM est indispensable. Il compare les données non structurées à un ensemble de références hachées, ce qui réduit les faux positifs à presque zéro et permet de vérifier les données critiques avec précision.
- Classification assistée par l’IA/LLM : l’IA excelle lorsqu’il y a ambiguïté. C’est un outil puissant pour catégoriser de nouveaux types de données, interpréter des schémas incohérents ou ajouter du contexte aux résultats de classification. Associée à la logique des modèles, l’IA améliore la précision et l’exploitabilité globales, en particulier pour les données ambiguës ou en évolution.
La réalisation de l'échelle et de la précision dépend de l'utilisation des méthodes de classification appropriées
Conclusion : utilisez d’abord la méthode la plus rapide et la plus précise (modèles), ajoutez l’EDM pour une certitude absolue, puis ajoutez l’IA pour une compréhension contextuelle approfondie.
Une approche concrète pour la découverte et la classification des données
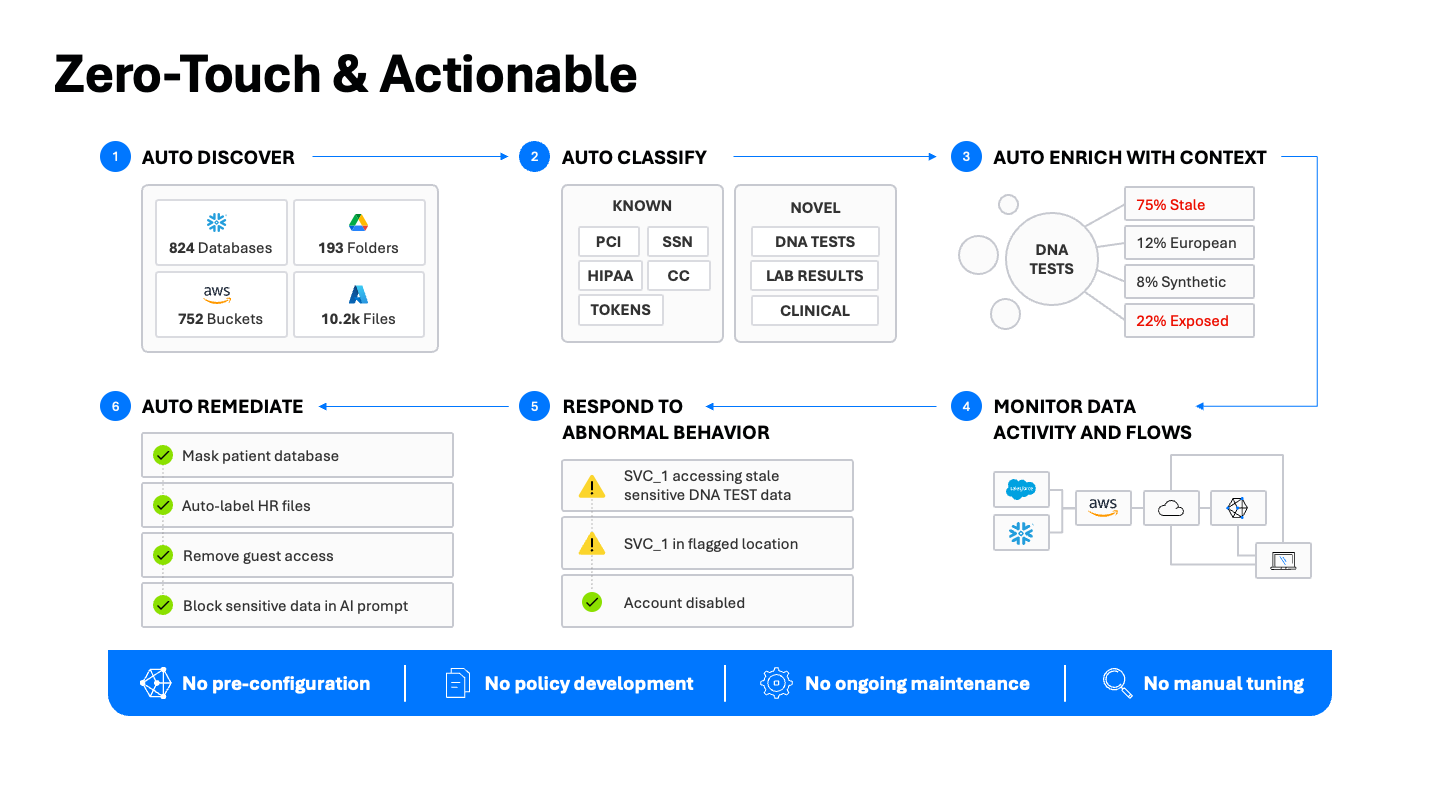
La découverte et la classification des données ne concernent pas uniquement la visibilité. Elles portent également sur la sécurisation des informations. La plateforme de sécurité des données Varonis offre une approche complète de la sécurité des données, de la découverte à la remédiation, conçue pour réduire les efforts manuels et accélérer les résultats en matière de sécurité à chaque étape.
- Détection automatique des dépôts de données : cartographiez automatiquement les données de votre parc informatique, y compris celles stockées dans le cloud, dans des solutions SaaS et dans des environnements hybrides. Des centaines de bases de données, des milliers de compartiments et d’innombrables partages de fichiers sont répertoriés en permanence.
- Classification automatique avec le meilleur outil : commencez par une analyse complète pour établir une base de référence, en utilisant une combinaison de correspondance de modèles, de correspondance exacte des données (EDM) et de classification assistée par l’IA pour garantir la précision. Ensuite, évoluez efficacement grâce à une analyse incrémentielle, en tirant parti des logs natifs pour détecter les changements et analyser uniquement les éléments nouveaux ou modifiés.
- Enrichir le contexte : allez au-delà du type de données pour enrichir le contexte avec le sujet, le thème et les réglementations applicables. Un fichier ne contient pas « seulement des informations personnelles identifiables ». Il contient un « formulaire d’admission de patient contenant des données réglementées par la loi HIPAA ». Ce contexte est essentiel pour informer la sécurité des données exploitables.
- Surveiller l’activité et les flux de données : maintenez une piste d’audit unifiée qui met en corrélation les données, l’identité, le réseau et la télémétrie de sensibilité afin de voir comment les données classifiées sont utilisées, où elles sont transférées et par qui, y compris les interactions immédiates avec l’IA.
- Réagir aux comportements anormaux : une classification précise alimente le DLP et la modélisation des risques, permettant à l’UEBA de mettre en évidence les comportements complexes des adversaires. Enrichissez les alertes avec un contexte de classification pour détecter les exfiltrations, les menaces internes et les utilisations abusives des outils d’IA. Hiérarchisez les alertes en fonction de leur rayon d’action et de leur degré de fiabilité, et accélérez les enquêtes grâce au MDDR 24h/24 7j/7 de Varonis.
- Remédiation automatique : les résultats de la classification doivent se traduire directement par des améliorations en matière de sécurité. C’est là qu’intervient la remédiation automatisée. Masquez automatiquement les données sensibles, étiquetez automatiquement les fichiers HR, supprimez les accès invités à risque et empêchez les données sensibles d’entrer dans les invites IA sans créer de tickets de service inutiles ou d’intégrations complexes.
Notre principe de fonctionnement est clair : pas de préconfiguration, pas de maintenance continue des politiques, pas de réglage manuel — juste un déploiement rapide et facile et une valeur immédiate.
Déploiement sécurisé et résidence des données
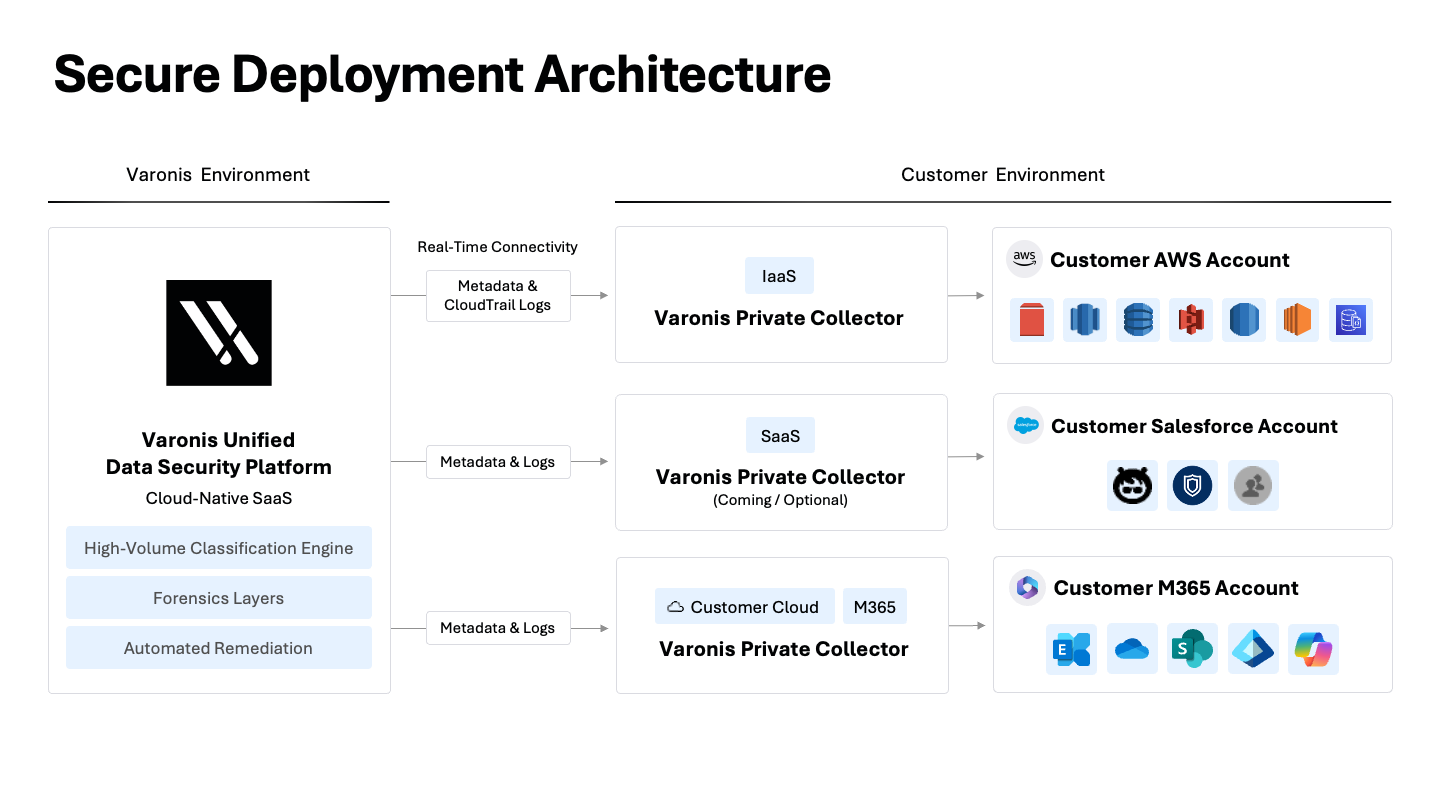
La manière dont vos données sont analysées est importante. Pour faciliter la mise à l’échelle, de nombreux fournisseurs transfèrent directement vos échantillons de données vers leur cloud afin de les classer. Cela crée un risque pour la confidentialité, augmente votre surface d’attaque et vous fait perdre le contrôle de vos données. Si la résidence des données est une préoccupation, le transfert direct de données ne devrait pas être envisagé.
L’approche de Varonis comprend une isolation robuste des tenants, un traitement au sein de la région afin de respecter les exigences en matière de résidence des données, ainsi qu’un chiffrement pendant le transfert et au repos. Contrairement à d’autres fournisseurs, les données des clients ne sont jamais utilisées pour entraîner nos modèles d’IA.
Pour les organisations soumises à des règles strictes en matière de résidence des données, notre architecture de collecte de données leur permet de traiter et de classer les informations sans jamais quitter leur environnement.
Pour en savoir plus sur nos pratiques en matière de sécurité, nos certifications de conformité et nos politiques de confidentialité, nous vous invitons à consulter le Centre de confiance Varonis.
De la classification au contrôle : résultats concrets
La classification automatisée des données offre bien plus qu’une simple visibilité ; elle permet d’obtenir des résultats essentiels en matière de sécurité. Voici à quoi cela ressemble dans la réalité :
Cas d’utilisation : l’hôpital Tampa General déploie l’IA en toute sécurité
Défi : déployer Microsoft 365 Copilot auprès de 10 000 membres du personnel clinique et administratif sans exposer les données sensibles des patients (PHI).
Solution :
- Identifier les risques : découverte et classification automatiques de millions de fichiers contenant des informations médicales confidentielles qui étaient dangereusement surexposées.
- Résolution du problème : remise en conformité des autorisations avec un modèle de privilèges minimaux en quelques jours, verrouillage des données des patients avant le déploiement de l’IA.
- Alerter sur les risques liés aux données : surveillance continue de toutes les activités liées aux données et des instructions à l’IA après le déploiement afin de détecter et d’arrêter en temps réel tout accès anormal ou partage risqué.
Résultat : Tampa General a déployé avec succès et en toute confiance des assistants IA dans toute l’organisation, favorisant ainsi l’innovation tout en garantissant la sécurité et la conformité HIPAA de ses données les plus sensibles.
Cas d’utilisation : l’une des plus grandes coopératives de crédit américaines déploie une solution DLP d’entreprise
Défi :
Déployer des contrôles DLP pour protéger les informations personnelles identifiables (PII) et les données des cartes de paiement des membres contre les menaces internes et externes, tout en garantissant la conformité réglementaire.
Solution :
- Identifier les risques : découverte et classification de millions de fichiers contenant des données PII et PCI, fournissant ainsi la base nécessaire à une protection DLP précise et mettant en évidence un accès ouvert généralisé.
- Résolution du problème : réduire l’accès ouvert de 93 % grâce à une remédiation automatisée basée sur le principe du moindre privilège, garantissant que seuls les utilisateurs autorisés conservent leur accès.
- Alerter sur les risques liés aux données : surveillance en temps réel des activités liées aux données et intervention de l’équipe IR de Varonis pour enquêter sur trois incidents distincts.
Résultat : la coopérative de crédit a déployé le DLP en toute confiance, réduisant ainsi le risque de fuite tout en garantissant la sécurité des données sensibles des membres et leur conformité avec les réglementations telles que le CCPA.
La formule est simple : utiliser une classification précise pour identifier les risques, corriger les vulnérabilités et signaler les activités suspectes.
Comment la classification permet une IA sûre et des contrôles en aval
La découverte et la classification des données sont essentielles pour exploiter en toute sécurité les assistants IA tels que Microsoft 365 Copilot, ChatGPT Enterprise et Salesforce Agentforce. Vous ne pouvez pas protéger ce que vous ne connaissez pas. Il est essentiel d’identifier les données sensibles afin d’appliquer les contrôles appropriés et d’empêcher l’IA de les exposer.
Mais son impact va bien au-delà de l’IA. Une classification précise renforce vos contrôles en aval les plus critiques : elle ajoute un contexte haute fidélité à la détection et à la réponse aux menaces, permet une protection efficace contre la fuite de données, renforce les programmes de gestion des risques internes et rend possible l’automatisation du cycle de vie des données.
La classification de la vérité terrain permet de mettre en place des garde-fous adéquats. Elle garantit la protection des données sensibles contre toute exposition ou utilisation abusive, quel que soit leur emplacement ou les agents IA que vous déployez.
Vous souhaitez découvrir une classification qui donne des résultats ?
Cessez de gérer des politiques et commencez à gérer les risques.
Effectuez une évaluation gratuite des risques sur vos données pour obtenir une vue d’ensemble complète, actualisée et contextualisée de vos données, ainsi que des recommandations claires sur les mesures à prendre en matière de protection de l’IA et de DLP.
Veuillez noter que cet article a été traduit avec l'aide de l'IA et révisé par un traducteur humain.







.png)
.png)