
A descoberta e a classificação de dados formam a base para a segurança, a conformidade e a adoção segura da IA. Alcançar resultados como privilégio mínimo, DLP eficaz e uso seguro de ferramentas, como o Microsoft Copilot, requer uma classificação precisa, escalável e automatizada. Com o rápido influxo de IA, as apostas são ainda mais altas. A IA leva a uma explosão nos volumes de dados e oferece aos agentes maliciosos novas maneiras de localizar e exfiltrar dados confidenciais.
Apesar da importância da classificação de dados, ela continua a ser um desafio contínuo para a maioria das organizações. Elas têm dificuldade para responder a perguntas simples como "onde estão meus dados confidenciais?" e "que tipo de dados confidenciais eu tenho?"
Não há uma solução milagrosa para a descoberta e classificação eficazes de dados. Você não pode simplesmente aproveitar abordagens antigas ou seguir as últimas tendências do mercado. Para construir uma base eficaz para segurança, conformidade e adoção segura de IA, você precisa da ferramenta certa para esse trabalho.
Neste blog, vamos detalhar as abordagens para a descoberta e classificação de dados e como encontrar a combinação certa para ter precisão e escala.
Armadilhas comuns na descoberta e classificação de dados
A maioria dos projetos de descoberta e classificação de dados fracassa ou nunca sai do papel. Eles se concentram basicamente em uma única técnica e recorrem a atalhos para serem escaláveis. Em última análise, essas abordagens resultam em uma base fraca para a segurança de dados que coloca em risco os dados críticos. Vamos dar uma olhada nessas armadilhas comuns.
A abordagem legada que usa apenas RegEx
Alguns fornecedores dependem exclusivamente de expressões regulares (regex) para classificação. Embora seja eficaz e escalável para encontrar padrões previsíveis, essa abordagem enfrenta dificuldades com ambiguidade, contexto e novos tipos de dados. Além disso, essas regras frequentemente exigem ajustes manuais por equipes especializadas para acompanhar novos tipos de dados, sobrecarregando as equipes de segurança com a gestão contínua de políticas e falsos positivos.
A armadilha apenas de IA
Há muito burburinho em torno dos grandes modelos de linguagem (LLMs) e sua capacidade de compreender o contexto e a semântica. Embora os LLMs possam classificar novos tipos de dados com eficácia, confiar apenas na IA para a classificação é arriscado. Esses modelos exigem dados de treinamento bem selecionados, muitas vezes específicos do setor ou da empresa, para oferecer resultados precisos e evitar erros de suposições ou alucinações.
Se um fornecedor classifica dados sem um modelo devidamente treinado, o resultado não é confiável e pode aumentar rapidamente os custos em escala. Simplificando, a IA não é eficiente para a identificação determinística e de alta precisão de padrões bem conhecidos, o que constitui a maior parte da descoberta e classificação de dados. Apesar do burburinho, é essencial ter em mente que o objetivo é a precisão e a eficiência, não apenas a "IA".
O atalho de amostragem
Quando o principal argumento de venda de um fornecedor é a velocidade de escaneamento, isso geralmente sinaliza um atalho arquitetural: a amostragem Para conseguir resultados rápidos em grandes volumes de dados, algumas plataformas evitam as exigências de recursos de varreduras completas e analisam apenas um subconjunto dos dados. Ainda que isso possa ser aceitável para uma varredura pontual, cria um fundamento inseguro para qualquer iniciativa de segurança permanente.
A amostragem cria pontos cegos por definição, tornando impossível manter a conformidade de nível de auditoria, impor políticas precisas e responder de forma eficaz a uma violação.
O objetivo real é ter uma classificação na qual se possa confiar. A descoberta e classificação de dados devem trazer uma visão completa, continuamente atualizada e contextual dos seus dados que possa ser escalada.
A solução: a ferramenta certa para o trabalho certo
Assim como você não usaria um martelo para apertar um parafuso, também não deveria usar um único método de classificação para cada tipo de dado. Uma abordagem escalável combina o melhor de vários mundos:
- Classificação baseada em padrões: a classificação baseada em padrões é essencial para tipos de dados estruturados, como números de cartão de crédito ou identificadores de saúde. Técnicas como correspondência de proximidade, palavras-chave negativas e verificação algorítmica (por exemplo, Luhn para cartões de crédito) oferecem alta precisão com baixo custo de computação.
- Correspondência Exata de Dados (EDM): quando é preciso certeza em nível de registro (por exemplo, 'este é o ID de paciente 22814 do nosso sistema de EMR mestre'), a EDM é indispensável. Ela compara dados não estruturados a um conjunto de referência com hash, gerando quase zero falsos positivos e verificando dados críticos com precisão.
- Classificação Assistida por AI/LLM: a IA se destaca quando há ambiguidade. É uma ferramenta poderosa para categorizar novos tipos de dados, interpretar esquemas inconsistentes ou adicionar contexto aos resultados da classificação. Estruturada com lógica de padrões, a IA eleva a precisão geral e a capacidade de ação, especialmente para dados ambíguos ou em evolução.
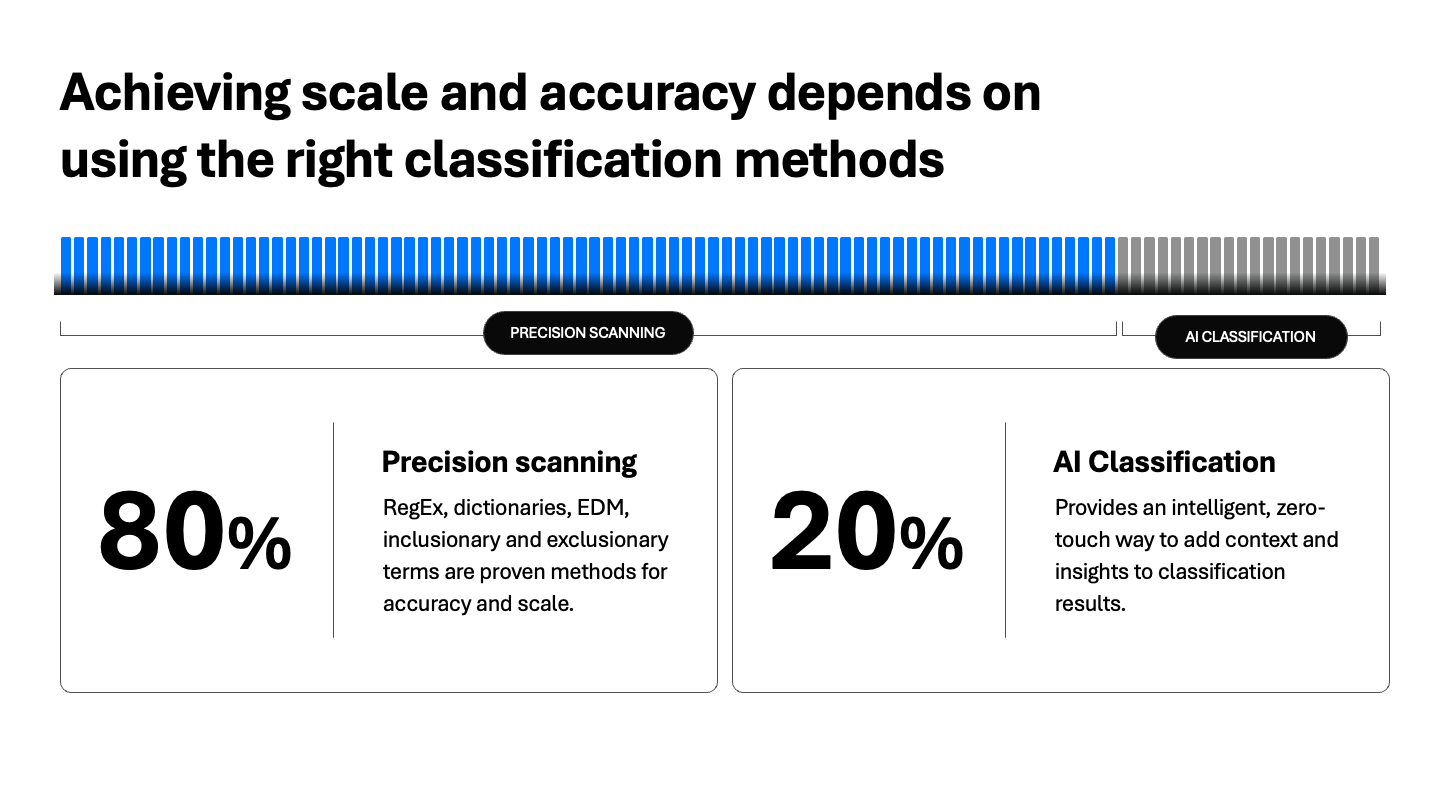
Alcançar escala e precisão depende do uso de métodos de classificação apropriados
Conclusão: use primeiro o método mais rápido e preciso (padrões), empregue o EDM para obter certeza absoluta e acrescente a IA para compreender o contexto profundamente.
Uma abordagem prática para a descoberta e classificação de dados
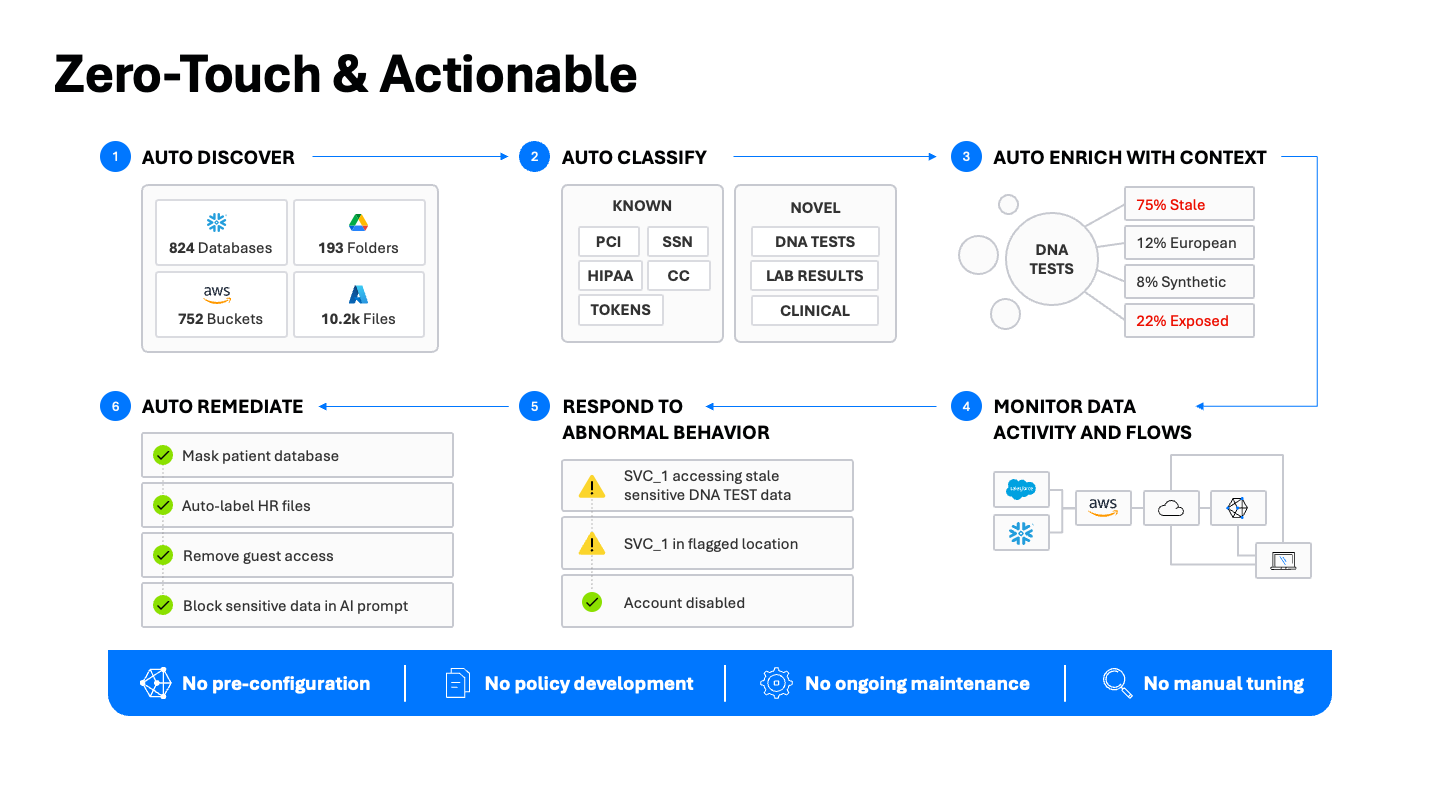
A descoberta e classificação de dados não se limitam apenas à visibilidade. Elas servem para proteger dados. A Plataforma de segurança de Dados Varonis oferece uma abordagem de ponta a ponta para a segurança de dados — da descoberta à remediação — criada para reduzir o trabalho manual e acelerar os resultados de segurança em cada etapa.
- Descoberta automática de repositórios de dados: mapeie automaticamente os dados em toda sua infraestrutura, incluindo nuvem, SaaS e ambientes híbridos. Centenas de bancos de dados, milhares de buckets e incontáveis compartilhamentos de arquivos, todos continuamente inventariados.
- Classifique automaticamente com a melhor ferramenta: comece com uma varredura completa e abrangente para estabelecer uma linha de base, usando uma combinação de correspondência de padrões, correspondência exata de dados (EDM) e classificação assistida por IA para garantir precisão. Em seguida, escale de forma eficiente com varredura incremental, aproveitando os logs de atividades nativos para detectar alterações e escanear apenas o que é novo ou modificado.
- Enriqueça com contexto: vá além do tipo de dado e enriqueça as descobertas com o tema, o tópico e as regulamentações aplicáveis. Um arquivo não apenas "contém IIP". Ele contém um “formulário de anamnese de pacientes contendo dados regulamentados pela HIPAA.” Esse contexto é crucial para orientar a segurança de dados de forma prática.
- Monitore a atividade e os fluxos de dados: mantenha uma trilha de auditoria unificada que correlacione dados, identidade, rede e telemetria de sensibilidade para ver como os dados classificados são usados, para onde se movem e por quem, incluindo interações de prompt de IA.
- Responda a comportamentos anormais: a classificação precisa potencializa o DLP e o modeling de risco, permitindo que a UEBA revele comportamentos adversários complexos. Enriqueça os alerts com contexto de classificação para detectar exfiltração, ameaças internas e uso indevido de ferramentas de IA. Priorize alerts por raio de exposição e confiança e acelere as investigações com Varonis 24x7 MDDR.
- Auto-remediar: os resultados da classificação devem se traduzir diretamente em melhorias na segurança. É aqui que entra a correção automatizada. Mascarar automaticamente dados confidenciais, rotular arquivos de RH automaticamente, remover acesso arriscado de convidados e evitar que dados confidenciais entrem em prompts de IA sem criar tíquetes de serviço desnecessários ou integrações complexas.
Nosso princípio operacional é firme: não há pré-configuração, manutenção contínua de políticas, nem ajuste manual — apenas implementação rápida e fácil e valor imediato.
Implantação segura e residência de dados
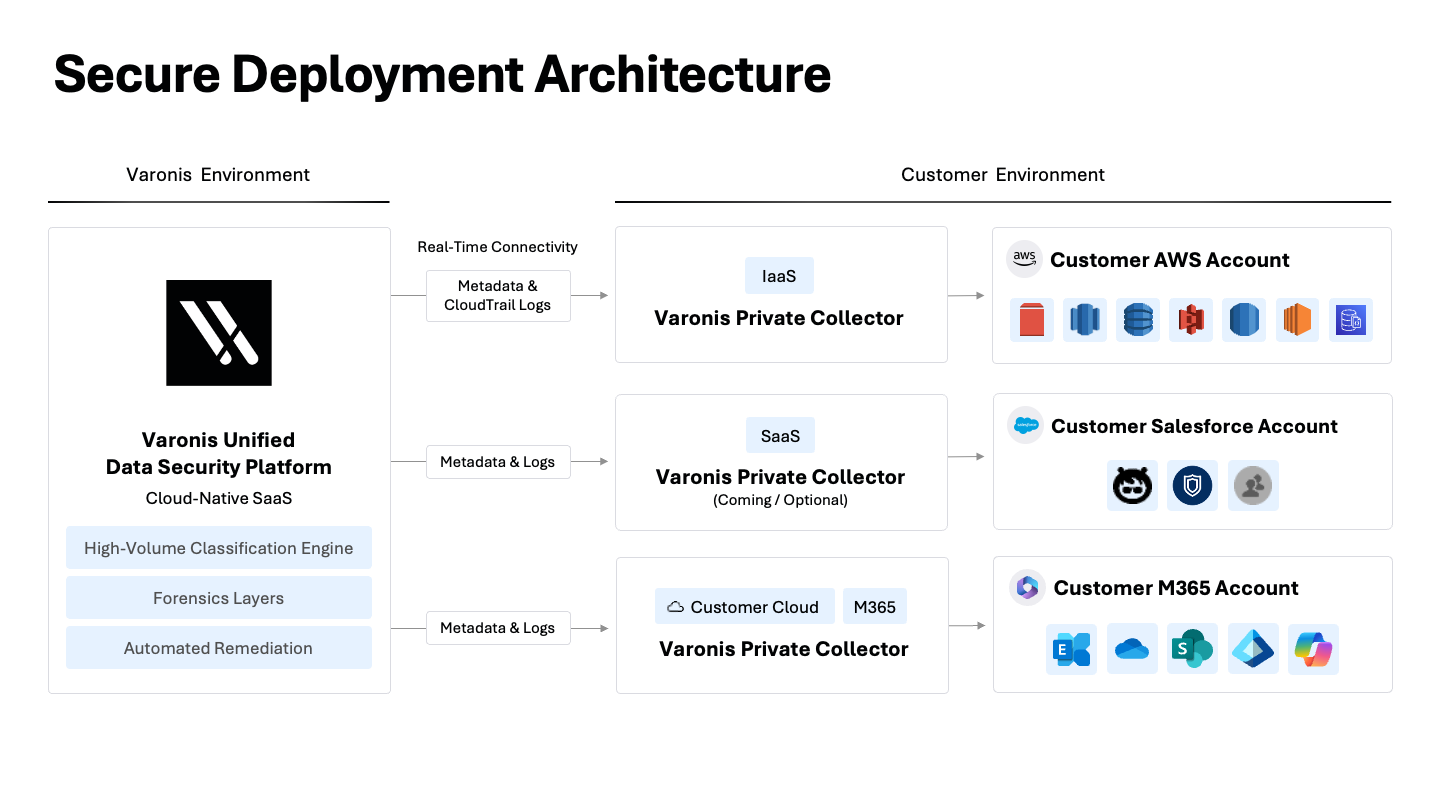
Como os seus dados são analisados, é importante. Para ajudar com a escala, muitos fornecedores transferem suas amostras de dados diretamente para a nuvem deles para serem classificadas. Isso cria risco de privacidade, aumenta a sua superfície de ataque e tira o controle dos seus dados. Se a residência de dados for uma preocupação, a transferência direta de dados deve ser descartada.
A abordagem da Varonis inclui isolamento robusto de tenants, processamento na região para atender aos requisitos de residência de dados e criptografia em trânsito e em repouso. Ao contrário de outros fornecedores, os dados dos clientes nunca são usados para treinar nossos modelos de IA.
Para organizações com regras rigorosas de residência de dados, a arquitetura do nosso coletor permite que estas processem e classifiquem informações sem que o conteúdo precise, sequer, sair do seu ambiente.
Para uma análise mais aprofundada das nossas práticas de segurança, certificações de conformidade e políticas de privacidade, recomendamos que você visite o Varonis Trust Center.
Da classificação ao controle: resultados no mundo real
A classificação automatizada de dados oferece mais do que apenas visibilidade; ela possibilita resultados críticos de segurança. Veja como isso acontece no mundo real:
Caso de uso: Tampa General Hospital implanta IA com segurança
Desafio: implementar o Microsoft 365 Copilot para 10.000 funcionários clínicos e de back-office sem arriscar a exposure de dados confidenciais de pacientes (PHI).
Solução:
- Encontre o risco: descobriu e classificou automaticamente milhões de arquivos contendo PHI que estavam perigosamente superexpostos.
- Corrija o problema: as permissões foram ajustadas para um modelo de privilégios mínimos em poucos dias, protegendo os dados dos pacientes antes da implantação da IA.
- Alerts sobre risco de dados: monitore continuamente todas as atividades de dados e prompts de IA após a implantação para detectar e interromper acessos anormais ou compartilhamentos arriscados em tempo real.
Resultado: a Tampa General implantou assistentes de IA com sucesso e confiança em toda a organização, permitindo a inovação e garantindo que seus dados mais confidenciais permanecessem seguros e em conformidade com a HIPAA.
Caso de uso: uma das maiores cooperativas de crédito dos EUA implementa DLP empresarial
Desafio:
Implementar controles DLP para proteger IIP dos membros e dados de cartões de pagamento contra ameaças internas e externas, garantindo a conformidade regulatória.
Solução:
- Encontrou o risco: descobriu e classificou milhões de arquivos contendo dados pessoais e de cartão de crédito, fornecendo a base para um DLP preciso e expondo o acesso aberto generalizado.
- Corrigiu o problema: reduziu o acesso aberto em 93% por meio da remediação automatizada de privilégios mínimos, garantindo que apenas usuários autorizados mantivessem o acesso.
- Alerts sobre risco de dados: manteve a supervisão em tempo real da atividade de dados e envolveu a equipe de resposta a incidentes da Varonis para investigar três incidentes separados.
Resultado: a cooperativa de crédito implementou o DLP com confiança, reduzindo o risco de violação e garantindo que os dados confidenciais dos membros permanecessem seguros e em conformidade com regulamentações como a CCPA.
A fórmula é simples: usar uma classificação precisa para encontrar o que está em risco, corrigir o que está exposto e receber alertas sobre atividades suspeitas.
Como a classificação possibilita uma IA segura e controles subsequentes
A descoberta e a classificação de dados são essenciais para usar assistentes de IA com segurança, como o Microsoft 365 Copilot, o ChatGPT Enterprise e o Salesforce Agentforce. Não é possível proteger o que você não conhece. Identificar dados confidenciais é crucial para aplicar os controles adequados e evitar que a IA os exponha.
Mas o impacto vai muito além da IA. A classificação precisa potencializa os seus controles downstream mais críticos: adiciona contexto de alta fidelidade à detecção e resposta a ameaças, permite um DLP eficaz, fortalece os programas de risco interno e possibilita a automação do ciclo de vida dos dados.
A classificação de referência é como você constrói barreiras de proteção adequadas. Ela garante que os dados confidenciais sejam protegidos contra exposure ou uso indevido, não importa para onde eles vão ou quais agentes de IA você implemente.
Pronto para ver a classificação que traz resultados?
Pare de gerenciar políticas e comece a gerenciar o risco.
Realize um relatório de risco de dados gratuito para obter uma visão completa, atual e contextual de seus dados, além de etapas claras para proteções de IA e DLP.
Nota - Este artigo foi traduzido com a ajuda de IA e revisado por um tradutor humano.








