
At the Inside Out Security blog, we’re always preaching the importance of risk assessments. IT and the C-levels need to evaluate vulnerabilities in their corporate systems to determine risk factors. Some of our favorite examples of cyber risk factors are sensitive data that has global access, stale data that’s no longer needed, and overly generous file permission.
To help you get a handle on security risk assessments, I wrote up a series of posts that organized the relevant risk controls from several popular standards into four broader categories: identify, protect, detect, and respond. And then I conveniently explained how Varonis can help in each of these areas.
Get the Free Pen Testing Active Directory Environments EBook
Relationship Between Risk Assessment and Risk Analysis
But there’s a part of the assessment process that doesn’t receive nearly the attention it should … and that is the actual risk analysis or risk model.
What’s the difference between these two?
Risk analysis takes the risk factors discovered during the identify phase as input to a model that will generate quantifiable measurements of cyber risk. With numeric results from the risk model, you then make comparisons: for example, is my risk profile better or worse this year than last?
Before we get into how a risk model might work, I need to zoom into another area of risk assessment that’s been neglected: threat analysis!
To do a thorough risk assessment, you need to look outside the organization to review the external threat landscape relevant to your industry or situation: attack methods, types of malware employed, and the possible actors. Technically, this is also part of the identify phase of the assessment: in addition to inventorying internal data and systems, you also review the threats you’re facing.
Threat models, by the way, are a very useful way to organize and view a threat landscape.
We now have all the ingredient to conduct a real risk analysis. Informally, a risk analysis tells you the chances a company will get hit with, say, a ransomware or Denial of Service (DoS) attack, and then calculates the financial impact on the business.
Thankfully, the security researchers at our National Institute of Standards and Technology or NIST have some great ideas on both risk assessments and risk models. In fact, I borrowed their assessment control classification for the aforementioned blog post series.
They are also a wonderful source of risk-related resources. One of the documents I came across, Guide for Conducting Risk Assessments, is a great overview of the entire risk assessment and risk analysis process. Very much worth a review.
A good risk graphic is always worth volumes of risk prose. Please gaze upon the following graphic from the NIST document — it illustrates what I was trying to explain above.
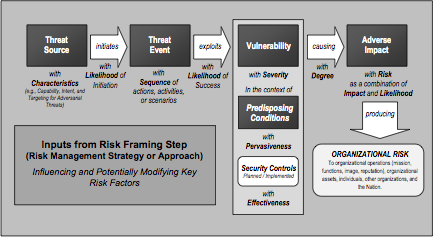
Risk Modeling: Likelihood of Event Occurrence and Impact Level
When we start looking more closely at risk analysis, the phrases “likelihood of occurrence” and “level of impact” inevitably start entering the discussion. As the NIST folks put it, “risk is a function of the likelihood of a threat event’s occurrence and potential adverse impact should the event occur.”
The above graphic visually summarizes what quantitative risk modeling is all about. You can get lost in the details as I did with my own mathy modeling in this blog series. But a risk analysis model should minimally produce an average incident cost over some time period. As we’ll see in my follow-up post, we can do a little better by working out a range of costs with some confidence or probability level.
The point of this post is to try to convince you that you have more information on your hands to assign meaningful numeric values to both likelihood of occurrence and level of impact! And that you should get away from the red-yellow-green risk matrix that often shows up when IT departments take an initial dip into risk modeling.
Ever seen one of these?
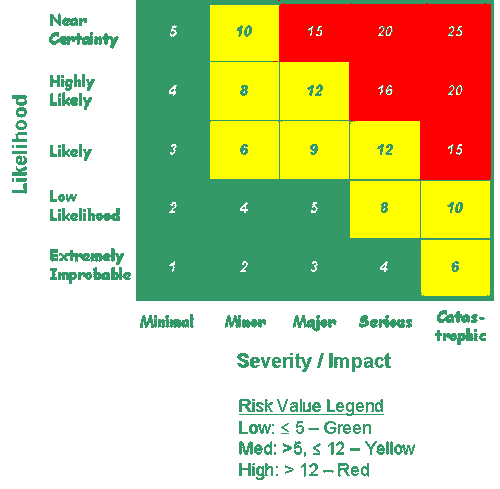
I’ve taken the above risk-matrix graphic from a US government website involving transportation risk. However, the risk concepts are universal and similar matrices are used — really misused — by IT departments.
One axis assigns a likelihood of an incident on a 1-5 numeric scale, with 1 being extremely improbable and 5 being close to certain. And the second axis — going horizontally in the graphic above — assigns a scale from 1 – 5 for the level of impact. You’ll notice that cells in the matrix are given numeric values for total risk based on multiplying the small integer values for the likelihood of the event by the impact.
In the top right-hand corner, there’s a “risk” of 25 for an event that is highly probable and very impactful. And in the bottom left-hand cell, there’s a risk value of 1 for low-probability and low-impact incident. By referring to the matrix index, you see the basis of the coloring scheme: high risk is assigned red, then yellow, and finally green for risks below a value of 5.
Let’s be blunt: these red-yellow-green risk matrix charts are a bad idea. They give you a false sense of having quantified risk — you’re not even using probabilities! — and they turn out to be very unconvincing to C-levels who are not interested in numbers that don’t relate to actual costs.
Your Company Can Too Quantify Risk: Talk to Your Sys Admins
There is a better way. I’m inspired in my thinking about risk analysis by two risk pros, Doug Hubbard and Richard Seiersan. Their book, How to Measure Anything in Cybersecurity Risk, is a great overview of this subject and includes very practical advice on conducting practical risk modeling.
Hubbard and Seiersan’s key insight is that you can start assigning real probabilities and cost impacts to events even if you have very little information! The book provides the theoretical background for this approach.
How do you begin quantifying likelihood of an attack and the cost of impact?
The answers can be found by interviewing your IT staff and other internal experts.
Hubbard believes that even minimal data obtain from interviews and available records can be used for modeling purposes, which is far more powerful approach than the red-yellow-green matrix.
Hubbard believes in getting corporate IT to assign a “90% confidence interval” to their answers. It’s perfectly legitimate to ask sys admins, “Can you put a range on how long service outages have been in the last 5 years?” They can review their own data and notes, and perhaps decide that most of the outages have been between, say, 1 hour and 10 hours. If we’re talking about an online retailer, the outages translate directly into lost sales, and now we have a range of cost impacts!
Where is all this going?
In my follow-up post, I will translate these ideas on confidence intervals, incident costs, and event likelihoods to model, using an Excel spreadsheet, a ransomware or DoS attack to produce some useful results that CFOs and CEOs will love. I’ll need to dip into the Hubbard book for a teeny bit of math background but nothing to scare anyone off.
In the meantime, if you’re curious about the current state of corporate security risk, please download our 2019 Global Risk Report.








-1.png)