
One (of the many) confusing aspects of the EU General Data Protection Regulation (GDPR) is its “right to be forgotten”. It’s related to the right to erasure but takes in far more ground. The right to have your personal deleted means that data held by the data controller must be removed on request by the consumer. The right to be forgotten refers more specifically to personal data the controller has made public on the Intertoobz.
Simple, right?
Get the Free Essential Guide to US Data Protection Compliance and Regulations
It ain’t ever that easy.
I came across a paper on this subject that takes a deeper look at the legal and technical issues around erasure and “forgetting”. We learn from the authors that deleting means something different when it comes to big data and artificial intelligence versus data held in a file system.
This paper contains great background on the recent history of the right to be forgotten, which is well worth your time.
Brief Summary of a Summary
Way back in 2010, a Mr. Costeja González brought a complaint against Google and a Spanish newspaper to Spain’s national Data Protection Authority (DPA). He noticed that when he entered his name into Google, the search results displayed a link to a newspaper article about a property sale made by Mr. González to resolve his personal debts.
The Spanish DPA dismissed the complaint against the newspaper —they had legal obligation to publish the property sale. However, the DPA allowed the one against Google to stand.
Google’s argument was that since it didn’t have a true presence in Spain – no physical servers in Spain held the data – and the data was processed outside the EU, it wasn’t under the EU Data Protection Directive (DPD).
Ultimately, the EU’s highest judicial body, the Court of Justice, in their right to be forgotten ruling in 2014 said that: search engine companies are controllers; the DPD applies to companies that market their services in the EU (regardless of physical presence); and consumers have a right to request search engine companies to remove links that reference their personal information.
With the GDPR becoming EU law in May 2018 and replacing the DPD, the right to be forgotten is now enshrined in article 17 and the extraterritorial scope of the decision can be found in Article 3.
However, what’s interesting about this case is that the original information about Mr. Gonzalez was never deleted — it still can be found if you search the online version of the newspaper.
So the “forgetting” part means, in practical terms, that a key or link to the personal information has been erased, but not the data itself.
Hold this thought.
Artificial Intelligence Is Like a Mini-Google
The second half of this paper starts with a very good computer science 101 look at what happens when data is deleted in software. For non-technical people, this part will be eye opening.
Technical types know that when you’re done with a data object in an app and after the memory is erased or “freed”, the data does not in fact magically disappear. Instead, the memory chunk is put on a “linked list” that will eventually be processed and then made part of available software memory to be re-used again.
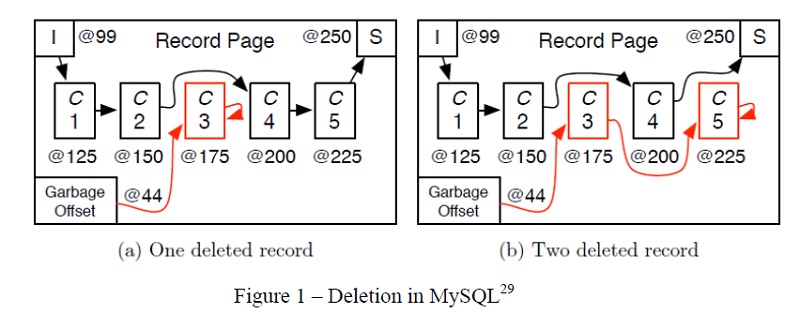
This procedure is known as garbage collection, and it allows performance-sensitive software to delay the CPU-intensive data disposal to a later point when the app is not as busy.
Machine learning uses large data sets to train the software and derive decision making rules. The software is continually allocating and deleting data, often personal data, which at any given moment might be on a garbage collection queue waiting to be disposed.
What does it mean then to implement right to be forgotten in an AI or big data app?
The authors of the paper make the point that eliminating a single data point is not likely to affect the AI software’s rules. Fair enough. But certainly if tens or hundreds of thousands use their right to erase under the GPDR, then you’d expect some of these rules to shift.
They also note that data can be disguised through certain anonymity techniques or pseudonymization as a way to avoid storing identifiable data, thereby getting around the right to be forgotten. Some of these anonymity techniques involve adding “noise” which may affect the accuracy of the rules.
This leads to an approach to implementing right to be forgotten for AI that we alluded to above: perhaps one way to forget is to make it impossible to access the original data!
A garbage collection process does this by putting the memory in a separate queue that makes it unavailable to the rest of the software—the software’s “handle” to the memory no longer grants access. Google does the same thing by removing the website URL from its internal index.
In both cases, the data is still there but effectively unavailable.
The Memory Key
The underlying idea behind AI forgetting is that you remove or delete the key that allows access to the data.
This paper ends by suggesting that we’ll need to explore more practical (and economic) ways to handle right to be forgotten for big data apps.
Losing the key is one idea. There are additional methods that can be used: for example, to break up the personal data into smaller sets (or silo them) so that it is impossible or extremely difficult to re-identify each separate set.
Sure removing personal data from a file system is not necessarily easy, but it’s certainly solvable with the right products!
Agreed: AI forgetting involves additional complexity and solutions to the problem will differ from file deletion. It’s possible we’ll see some new erasure-like technologies in the AI area as well.
In the meantime, we’ll likely receive more guidance from EU regulators on what it means to forget for big data applications. We’ll keep you posted!

-1.png)




