Data discovery has become an important part of every data security program. From prioritizing efforts to tightening permissions to deciding where to place compensating controls, a map of sensitive data helps prioritize remediation of controls and informs detection.
In the cloud, basic data discovery is easier than in on-premises data stores. Where many on-prem systems lacked centralized hooks, rich APIs from cloud platform providers make it straightforward to enumerate objects and feed a sample of their contents to an LLM to classify. You can query containers and services for their configurations, and you have what many call “posture” in Data Security Posture Management (DSPM). Because of its low barrier to entry, multiple vendors offer these functions today with little variation between them.
However, these tools fail to take crucial next steps that are critical to secure enterprise data:
- Identifying which users can access that data and how
- Resolving which services act on behalf of which principals, and can access that data
- Reporting how the data is used, unused and misused
- Isolating what privileges can be safely removed without breaking something
Critically, real data security requires continuous activity monitoring and privilege pruning, which is not achievable with scheduled scans of data contents and surface-level posture.
The cloud-native break: when discovery stops being actionable
The rise of cloud-native architectures has fundamentally reshaped the relationship between data, identity, and access. There have been two major shifts:
- The amorphous nature of cloud data itself, and
- The fractured, multilayered access models that govern it
Together, they have broken the old linear process of discovery → review → remediation.
Data is no longer “file-shaped”
Historically, data adhered to predictable patterns; you had files and folders, databases and tables, star schemas and Snowflake schemas. These structures weren’t just organizational choices — they were artifacts of physical constraints. Block sizes, IOPS limits, network bottlenecks, storage provisioning, and fixed compute all forced data to conform to stable, well-defined shapes. Importantly, files had a consistent interpretation format, and they were generally persistent.
Cloud storage removed all those constraints.
Object stores like S3, Azure Blob, and GCS don’t enforce schemas, directory structures, or size boundaries. Modern cloud-native data lakes, processing streams, and ML pipelines take full advantage of these new patterns, and generate ephemeral files, intermediate artifacts, and shadow datasets that appear and disappear constantly. Table formats like Apache Iceberg and compute layers like Athena dynamically overlay on top of each other and reinterpret raw objects as structured tables.
Access is no longer a single plane
In the on-premises world, access to data comes down to who has read or write permissions to this file, this folder, or this database? You evaluated the ACL, checked group membership, recursed if necessary, and you had the answer. Despite its straightforward arrangement, determining effective access is still a big challenge.
Cloud makes it more complex with multilayered, multiprincipal access models. Take S3 as an example. Access to the same dataset may be governed directly or indirectly by:
- A bucket policy
- An ACL
- An IAM role
- A cross-account trust
- A servicelinked role
- A crossaccount trust
- An Athena workgroup
- An Iceberg table definition
- A Lambda execution role
- A downstream application querying S3 indirectly
Imagine an S3 bucket with automated Airflow pipelines, one Glue job, a sparsely used Lamba function, with a querying interface provided by Athena. Now a discovery scan that says that this bucket has sensitive data in it, what would someone do with that information?
Probably ask more questions — who can and does use it? Why? The blast radius includes every ephemeral principal, every wrapper service, every compute layer, and every downstream consumer capable of reading or transforming that data — and this visibility can only be gained by continuously monitoring all activities against that bucket.
In cloud-native environments, discovery does not reveal risk — it reveals only the surface of a deeply interconnected ecosystem. And when typical discovery tools declare “you have a problem here,” they give you a help-desk ticket, not a fix. They don’t understand how identities interact with data, which services act on behalf of which principals, or how access paths propagate across compute layers.
Agents make metadata an attack vector
Modern systems, especially agentic AI, treat metadata as fuel. AI agents can read catalog descriptions, infer data value, map access paths, and automate reconnaissance. A catalog full of “PII,” “financial statements,” “executive compensation,” and “patient records” is a blueprint. If access isn’t remediated, discovery becomes an index of everything an attacker or rogue insider should investigate.
In other words, the more you know and fail to act on, the more dangerous the environment becomes. Discovery by itself is a liability.
Cloud-native security necessitates continuous monitoring and automated remediation. Attackers don’t manually browse folders anymore. AI does it for them. Sensitive data with excessive permissions is no longer a benign entry on a risk registry; it is an active risk that can be easily exploited by AI agents.
Why most vendors stop at discovery
If discovery is so limited in the cloud-native world, why do so many vendors anchor their offerings around it?
Because discovery is easy to demonstrate, easy to evaluate, and easy to commoditize. You can scan metadata. You can sample files. You can fingerprint schemas. You can tag objects. You can show dashboards. You can ship a report.
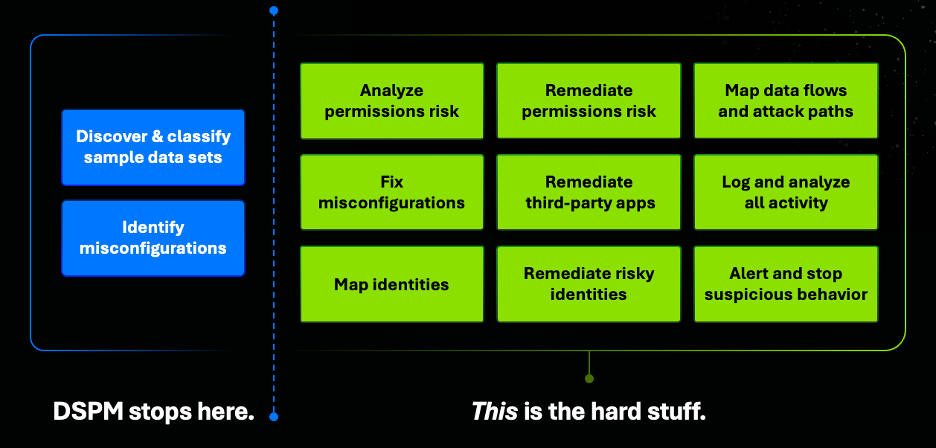
The hard part — and what’s needed to reduce risk — is the following:
- Providing visibility into permissions: this involves enumerating all entitlements associated with all identities
- Understanding how data is used: which requires monitoring all activity at scale
- Determining who should have access: which requires mature threat models and a bidirectional permissions analysis
- Reducing privileges safely: which involves resolving permissions across multiple enforcement layers and safely applying changes without breaking processes.
Most DSPM vendors hand customers a discovery report because monitoring activity is hard, and the remediation step is technically complex and operationally risky. It’s easier to say “here are a few things that might be broken in your environment” than to build a system that can safely find, prioritize, and fix them.
But cloud-native reality doesn’t allow for that split anymore. Discovery without remediation is not a first phase; it is unfinished work that becomes a liability for organizations.
The recipe for remediation at cloud scale
Remediation in cloud-native environments requires answers to questions that discovery tools cannot answer.
Who actually uses what data?
The theoretical access model (permissions) and the defacto access model (activity) diverge quickly in cloud-native environments. Temporary credentials, automated pipelines, service-to-service calls, and ephemeral access create a thicket of access signals that only behavior can reliably explain.
Understanding actual usage requires complete activity visibility, not samples.
What access is actually necessary?
Least privilege in the cloud cannot be defined statically. It must be inferred from real behavior:
- Which principals never touch certain datasets?
- Which policies are excessively broad?
- Which access paths were created for migration but persist indefinitely?
To safely remediate, you must continuously reconcile permissions with behavior. Static discovery cannot tell you what is safe to remove. Furthermore, modern data access must be analyzed from both directions:
- From principal → data: what can each identity theoretically reach?
- From data → principal: which identities use this dataset?
Effective remediation requires merging these two views continuously. Anything less, such as sampling, creates blind spots. And blind spots are where breaches happen.

Discovery is not a security outcome
Discovery demos well. It produces dashboards and numbers. This is why DSPM vendors emphasize discovery. But dashboards do not reduce risks, and statistics do not change access paths.
In the cloud, security failures are rarely caused by unknown data. They are caused by data that remains accessible. Once data is discovered, cataloged, and labeled, it becomes easier to reason about, easier to target, and easier to exploit — by attackers, by overprivileged services, and increasingly by autonomous systems that can enumerate access paths far faster than any human reviewer. Discovery that is not paired with activity, analysis, and remediation does not sit neutrally in the system; it amplifies exposure.
True data security is continuous by design:
- Continuous discovery, so new data is never invisible
- Continuous activity analysis, so data, accessibility, and access are understood contextually
- Continuous remediation, so risk is systematically reduced
These are not separate capabilities, stages, or SKUs. They are inseparable components of a single system whose purpose is not to describe risk, but to eliminate it.
This is the model Varonis was built for — not only to help organizations learn where sensitive data exists, but also to ensure that only the right identities can reach it, for the right reasons, for exactly as long as necessary.
In cloud-native environments, data security needs more than a discovery demo. Discovery without remediation is just liability. Busywork followed by a breach. And then a fine.








-1.png)