Imagine you’re the CISO of a 10,000-person organization where users create millions of files and emails each day. Some of that information is highly sensitive—if leaked or stolen, you’re facing a headline-making breach and seven-figure penalties. Most of the data created each day, however, could be published on the front page of the Times without incident.
It can be virtually impossible to prioritize risk mitigation or comply with privacy laws when you don’t know which information calls for military-grade protection. That’s where data classification comes in.
Want more insight into data security trends? Download our in-depth data breach statistics report.
Data Classification Definition

Data classification is the process of analyzing structured or unstructured data and organizing it into categories based on file type, contents, and other metadata.
Data classification helps organizations answer important questions about their data that inform how they mitigate risk and manage data governance policies. It can tell you where you are storing your most important data or what kinds of sensitive data your users create most often. Comprehensive data classification is necessary (but not enougdah) to comply with modern data privacy regulations.
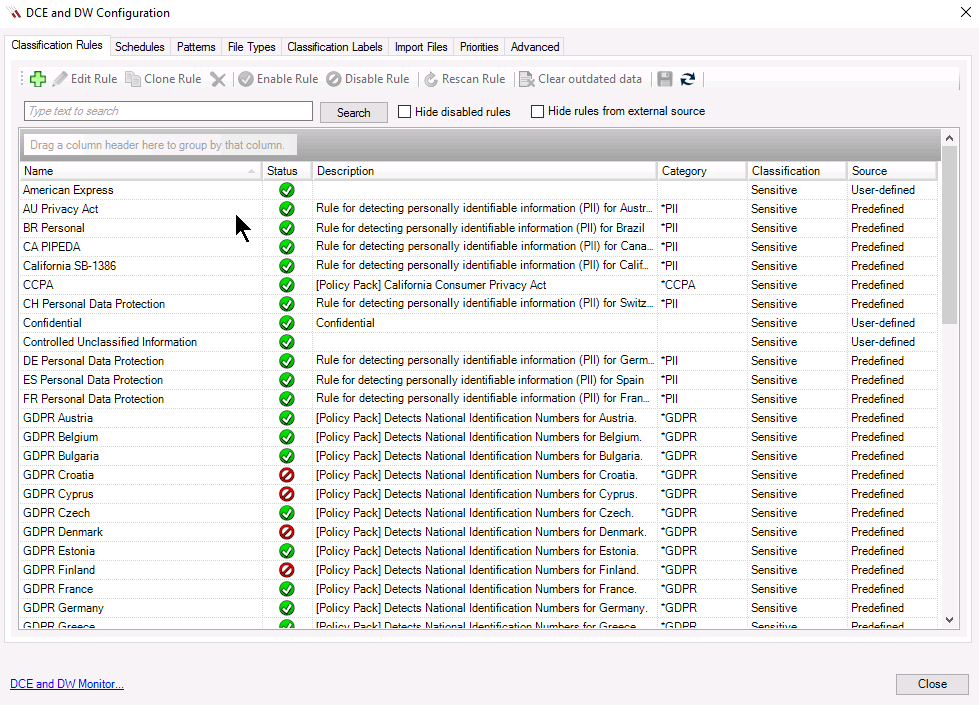
Data classification software allows organizations to identify information that is pertinent to an organization’s interests. For example, you may have a requirement to find all references to “Szechuan Sauce” on your network, locate all mentions of “glyphosate” for legal discovery, or tag all HIPAA related files on your network so they can be auto-encrypted.
To comply with data privacy regulations, organizations typically spin up classification projects to discover any personally identifiable information (PII) on your data stores so you can prove to auditors that it is properly governed.
Data classification is not the same as data indexing, although there are some parallels between the two. While both require looking at content to decide whether it is relevant to a keyword or a concept, classification doesn’t necessarily produce a searchable index.
In many cases, classification results will list the object name and the policy or pattern that was matched without storing an index of the object’s content:
- Object: Customers.xls
- Matched patterns: California Driver’s License (CCPA), American Express (PCI-DSS)
Some data classification solutions do create an index to enable fast and efficient search to help fulfill data subject access requests (DSAR) and right-to-be-forgotten requests.
Purpose of Data Classification

In the most recent Market Guide for File Analysis Software, Gartner lists four high-level use cases:
- Risk Mitigation
- Limit access to personally identifiable information (PII)
- Control location and access to intellectual property (IP)
- Reduce attack surface area to sensitive data
- Integrate classification into DLP and other policy-enforcing applications
- Governance/Compliance
- Identify data governed by GDPR, HIPAA, CCPA, PCI, SOX, and future regulations
- Apply metadata tags to protected data to enable additional tracking and controls
- Enable quarantining, legal hold, archiving and other regulation-required actions
- Facilitate “Right to be Forgotten” and Data Subject Access Requests (DSARs)
- Efficiency and Optimization
- Enable efficient access to content based on type, usage, etc.
- Discover and eliminate stale or redundant data
- Move heavily utilized data to faster devices or cloud-based infrastructure
- Analytics
- Enable metadata tagging to optimize business activities
- Inform the organization on location and usage of data
It’s important to note that classifying data—while a foundational first step—is not typically enough to take meaningful action to achieve many of the above use cases. Adding additional metadata streams, such as permissions and data usage activity can dramatically increase your ability to use your classification results to achieve key objectives.
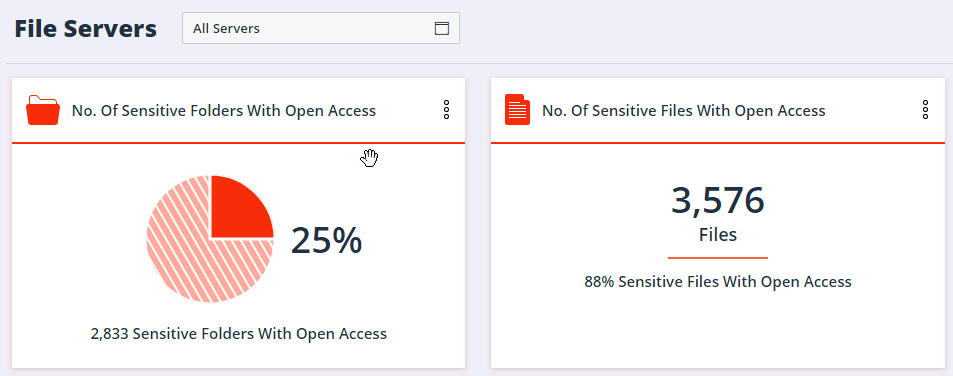
One of the most popular features of the Varonis Data Security Platform is a dashboard that reveals the subset of sensitive data that is also exposed to every employee so you know exactly where to start with your risk mitigation efforts.
Data Sensitivity Levels

Organizations often establish data sensitivity levels to differentiate how to treat various types of classified data. The United States government, for example, has seven levels of classification. They are, from highest to lowest:
- Restricted Data/Formerly Restricted Data
- Code Word classification
- Top Secret
- Secret
- Confidential
- Public Trust
- Controlled Unclassified Information (CUI)
Center for Internet Security (CIS) uses the terms “sensitive,” “business confidential,” and “public” for high, medium, and low classification sensitivity levels.
Three levels of classification are usually the right number for most organizations. More than three levels add complexity that could be difficult to maintain, and fewer than three is too simplistic and could lead to insufficient privacy and protection.
Here are recommended definitions for a classification taxonomy with three sensitivity levels:
- High Sensitivity Data: requires stringent access controls and protections both because it’s is often protected by laws such as GDPR, CCPA, and HIPAA and because it could cause significant harm to an individual or the organization if breached.
- Medium Sensitivity Data: intended for internal use only, but the impact of a data breach is not catastrophic. Examples are non-identifiable personnel data or architecture plans to a commercial building under development.
- Low Sensitivity Data: Low sensitivity data is public information that doesn’t require any access restrictions. Examples include public webpages, job postings, and blog posts.
You may use different nomenclature, and you may have more than three categories, depending on your use cases.
Types of Data Classification

There are two primary paradigms to follow when you implement a data classification process. There are others, but the majority of use cases will fall into one of these categories. You could task users with classifying the data they create, or you could do it for them with an automated solution.
User
When you task users to classify their own data, you need to define sensitivity levels, train your users to identify each level and provide a mechanism to tag and classify all new files they create.
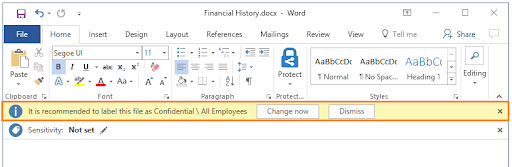
Most classification systems provide integrations to policy-enforcing solutions, such as data loss prevention (DLP) software, that track and protect sensitive data tagged by users. An example DLP policy might want block files tagged “High Sensitivity” from being uploaded to Dropbox.
The advantage of user classification is humans are pretty good at judging whether information is sensitive or not. With appropriate tooling and easy to understand rules, classification accuracy can be quite good, but it is highly dependent on the diligence of your users, and won’t scale to keep up with data creation.
Manually tagging data is tedious and many users will either forget or neglect the task. Also, if you have large amounts of pre-existing data (or machine-generated data), it is a monumental challenge to get users to go back and retroactively tag historical data.
Automated
Automated data classification engines employ a file parser combined with a string analysis system to find data in files. A file parser allows the data classification engine to read the contents of several different types of files. A string analysis system then matches data in the files to defined search parameters.
Automated classification is much more efficient than user-based classification, but the accuracy depends on the quality of the parser. Varonis’ Data Classification Engine includes a few key features to help validate results and decrease false positives—namely proximity of text, negative keywords, match ranges, and validation algorithms.
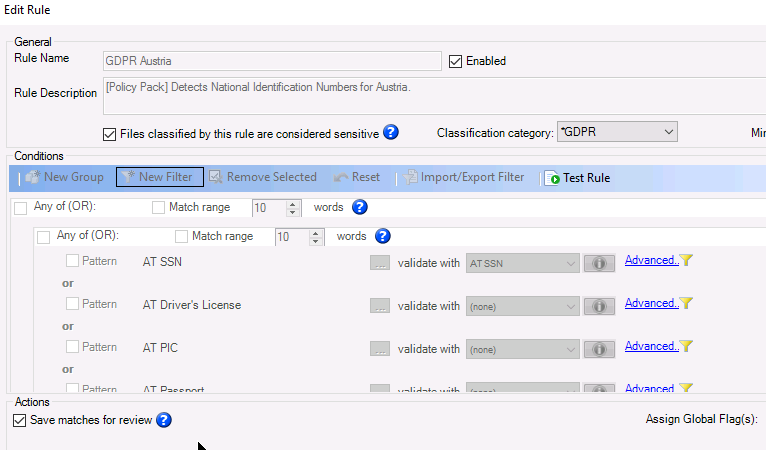
In addition to accuracy, efficiency and scalability are important considerations when selecting an automated classification product. For environments with hundreds of large data stores, you’ll want a distributed, multi-threaded engine than can tackle multiple systems at once without consuming too many resources on the stores being scanned.
The time to complete an initial classification scan of a large multi-petabyte environment can be significant. True incremental scanning can help speed up subsequent scans. Because Varonis monitors all data creates/modifies, our scanning engine scans only those files that are newly created or modified since the previous scan without having to check each file for a “date modified” timestamp.
Some classification engines require an index of each object they classify. If storage capacity is a concern, look for an engine that doesn’t require an index or only indexes objects that match a certain policy or pattern.
Organizations may settle on one or the other, or a combination of both user and automation classification. It’s always good to provide users with the training and functionality to engage in data protection, and it’s wise to follow up with automation to make sure things don’t fall through the cracks.
Data Classification Process

Data classification processes differ slightly depending on the objectives for the project. Most data classification projects require automation to process the astonishing amount of data that companies create every day. In general, there are some best practices that lead to successful data classification initiatives:
1. Define the Objectives of the Data Classification Process
- What are you looking for? Why?
- Which systems are in-scope for the initial classification phase?
- What compliance regulations apply to your organization?
- Are there other business objectives you want to tackle? (e.g., risk mitigation, storage optimization, analytics)
2. Categorize Data Types
- Identify what kinds of data the organization creates (e.g., customer lists, financial records, source code, product plans)
- Delineate proprietary data vs. public data
- Do you expect to find GDPR, CCPA, or other regulated data?
3. Establish Classification Levels
- How many classification levels do you need?
- Document each level and provide examples
- Train users to classify data (if manual classification is planned)
4. Define the Automated Classification Process
- Define how to prioritize which data to scan first (e.g., prioritize active over stale, open over protected)
- Establish the frequency and resources you will dedicate to automated data classification
5. Define the Categories and Classification Criteria
- Define your high-level categories and provide examples (e.g., PII, PHI)
- Define or enable applicable classification patterns and labels
- Establish a process to review and validate both user classified and automated results
6. Define Outcomes and Usage of Classified Data
- Document risk mitigation steps and automated policies (e.g., move or archive PHI if unused for 180 days, automatically remove global access groups from folders with sensitive data)
- Define a process to apply analytics to classification results
- Establish expected outcomes from the analytic analysis
7. Monitor and Maintain
- Establish an ongoing workflow to classify new or updated data
- Review the classification process and update if necessary due to changes in business or new regulations
Examples of Data Classification
RegEx –short for regular expression – is one of the more common string analysis systems that define specifics about search patterns. For example, if I wanted to find all VISA credit card numbers in my data, the RegEx would look like:
That sequence looks for a 16-character number that starts with a ‘4,’ and has 4 quartets delimited by a ‘-. ‘ Only a string of characters that matches the RegEx directly generates a positive result. Going a step further, this result can be validated by a Luhn algorithm.
Here is a case where a RegEx alone won’t do the job. This RegEx finds validate email addresses, but cannot distinguish personal from business emails:
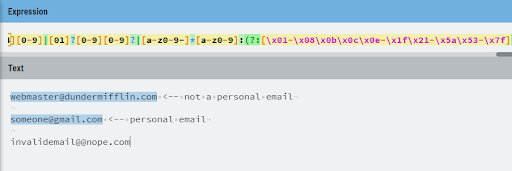
A more sophisticated data classification policy might use a RegEx for pattern matching and then apply a dictionary lookup to narrow down the results based on a library of personal email address services like Gmail, Outlook, etc.
In addition to regular expressions that look for patterns within text, many parsers will also look at a file’s metadata—like the file extension, owner, and extended properties—to determine its classification. Some scanning engines are robust enough to go beyond the contents of the file and incorporate permissions and usage activity into the classification rule.
Advanced data classification uses machine learning to find data without relying solely on predefined rules or policies made up of dictionaries and RegExes. For example, you might be able to feed a machine learning algorithm a corpus of 1,000 legal documents to train the engine what a typical legal document looks like. The engine can discover new legal documents based on its model without relying on string matching.
Data Classification Best Practices
Here are some best practices to follow as you implement and execute a data classification policy at scale.
- Identify which compliance regulations or privacy laws apply to your organization, and build your classification plan accordingly
- Start with a realistic scope (don’t boil the ocean) and tightly defined patterns (like PCI-DSS)
- Use automated tools to process large volumes of data quickly
- Create custom classification rules when needed, but don’t reinvent the wheel
- Adjust classification rules/levels as needed
- Validate your classification results
- Figure out how to best use your results and apply classification to everything from data security to business intelligence
Data classification is part of an overall data protection strategy. Once you know what data is sensitive, figure out who has access to that data, and what is happening to that data at all times. That way, you can protect your sensitive data and keep your organization from appearing in an unfortunate headline.
Data Classification Resources
- How to do Data Classification at Scale
- Data Classification Tips: Finding Credit Card Numbers
- Data Classification Labels
- CCPA Classification
- Data Privacy
- Data Governance
Data classification doesn’t have to be complicated. Varonis has the pre-built rules, intelligent validation, and proximity matching you need to do most of the work. Check out this Masterclass to see how customers classify their sensitive data.


-1.png)