
Data discovery and classification form the foundation for security, compliance, and safe AI adoption. Achieving outcomes like least privilege, effective DLP, and secure use of tools such as Microsoft Copilot requires accurate, scalable, and automated classification. With the rapid influx of AI, the stakes are even higher. AI leads to an explosion in data volumes and gives bad actors new ways to find and exfiltrate sensitive data.
Despite the importance of data classification, it remains a persistent challenge for most organizations. They struggle to answer simple questions like “where is my sensitive data?” and “what kind of sensitive data do I have?”
There is no silver bullet for effective data discovery and classification. You can’t simply leverage legacy approaches or chase the latest technology trend. To build an effective foundation for security, compliance, and safe AI adoption, you need the right tool for the job.
In this blog, we’ll detail the approaches to data discovery and classification and how to find the right combination for accuracy and scale.
Common pitfalls in data discovery & classification
Most data discovery and classification projects fail or never get off the ground. They focus too much on one technique and take shortcuts to reach scale. Ultimately, these approaches result in a poor foundation for data security that puts critical data at risk. Let’s take a look at these common pitfalls.
The legacy regex-only approach
Some vendors rely exclusively on regular expressions (regex) for classification. While effective and scalable for finding predictable patterns, this approach struggles with ambiguity, context, and novel data types. Furthermore, these rules often require manual tuning by specialized teams to keep up with new data types, burying security teams in perpetual policy management and false positives.
The AI-only trap
There’s a lot of buzz around large language models (LLMs) and their ability to understand context and semantics. While LLMs can classify novel data types effectively, relying solely on AI for classification is risky. These models require well-curated training data — often industry- or company-specific — to deliver accurate results and avoid errors from guesswork or hallucinations.
If a vendor classifies data without a properly trained model, the output is unreliable and can quickly drive up costs at scale. Simply put, AI isn’t efficient for deterministic, high-precision identification for well-known patterns, which constitutes the bulk of data discovery and classification. Despite the buzz, it’s essential to keep in mind that the goal is accuracy and efficiency, not just “AI.”
The sampling shortcut
When a vendor’s main selling point is scan speed, it often signals an architectural shortcut: sampling. To achieve fast results across large data estates, some platforms avoid the resource demands of full scans and analyze only a subset of the data instead. While that might be acceptable for a one-time snapshot, it creates a shaky foundation for any continuous security program.
Sampling creates blind spots by design, making it impossible to maintain audit-grade compliance, enforce precise policies, and respond effectively to a breach.
The real goal is classification you can trust. Data discovery and classification must provide a complete, continuously updated, contextual view of your data that scales.
The solution: The right tool for the right job
Just as you wouldn’t use a hammer to drive a screw, you shouldn’t use a single classification method for every data type. A scalable approach combines the best of multiple worlds:
- Pattern-Based Classification: Pattern-based classification is king for structured data types like credit card numbers or healthcare identifiers. Techniques like proximity matching, negative keywords, and algorithmic verification (e.g., Luhn for credit cards) deliver high precision at low compute cost.
- Exact Data Match (EDM): When record-level certainty is required (e.g., this is patient ID 22814 from our master EMR system), EDM is indispensable. It compares unstructured data to a hashed reference set, driving near-zero false positives and verifying critical data with precision.
- AI/LLM-Assisted Classification: AI shines when there is ambiguity. It is a powerful tool for categorizing novel data types, interpreting inconsistent schemas, or adding context to classification results. Layered with pattern logic, AI raises overall precision and actionability, especially for ambiguous or evolving data.
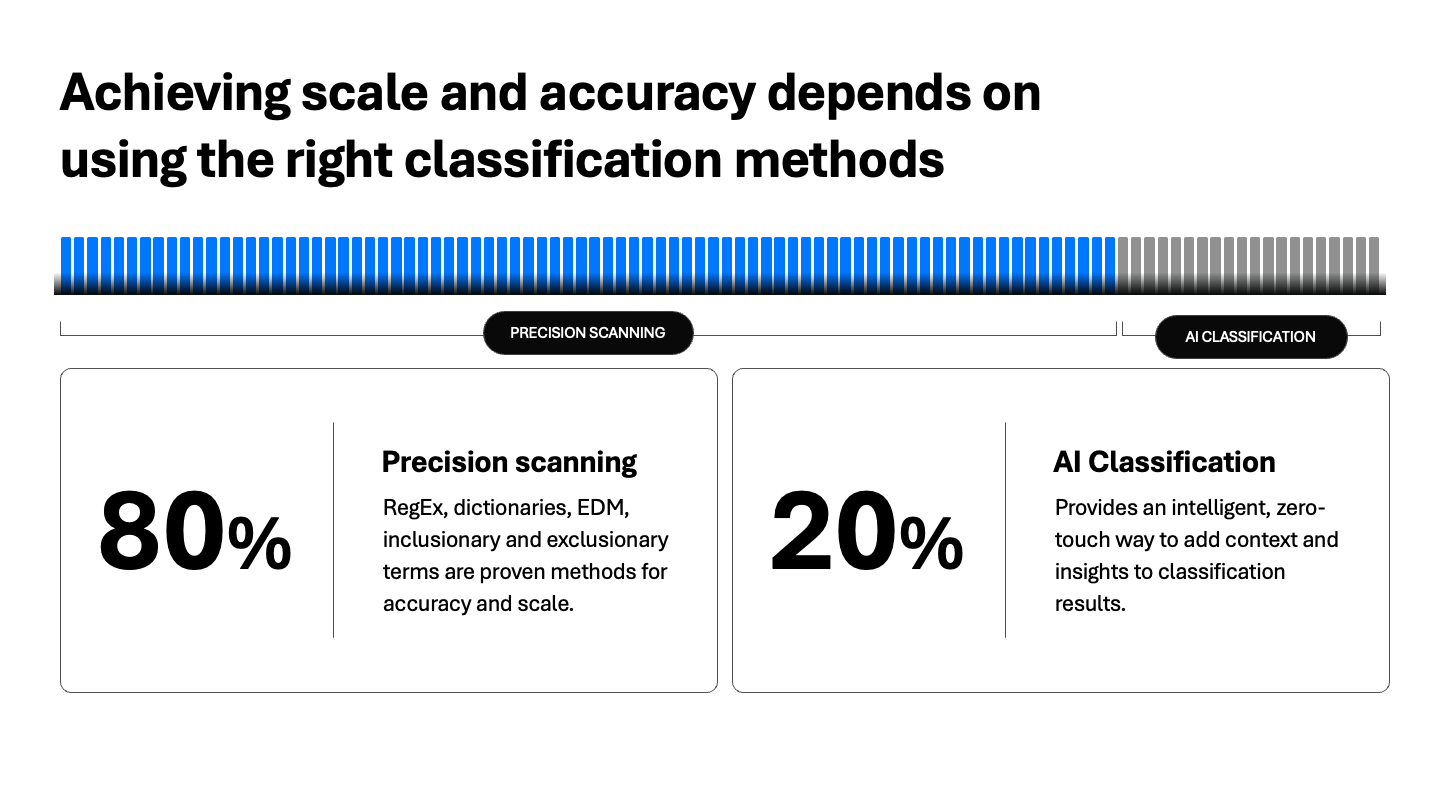
Achieving scale and accuracy depends on using the proper classification methods
Takeaway: Use the fastest, most accurate method first (patterns), bring in EDM for absolute certainty, and layer on AI for deep contextual understanding.
An actionable approach to data discovery and classification
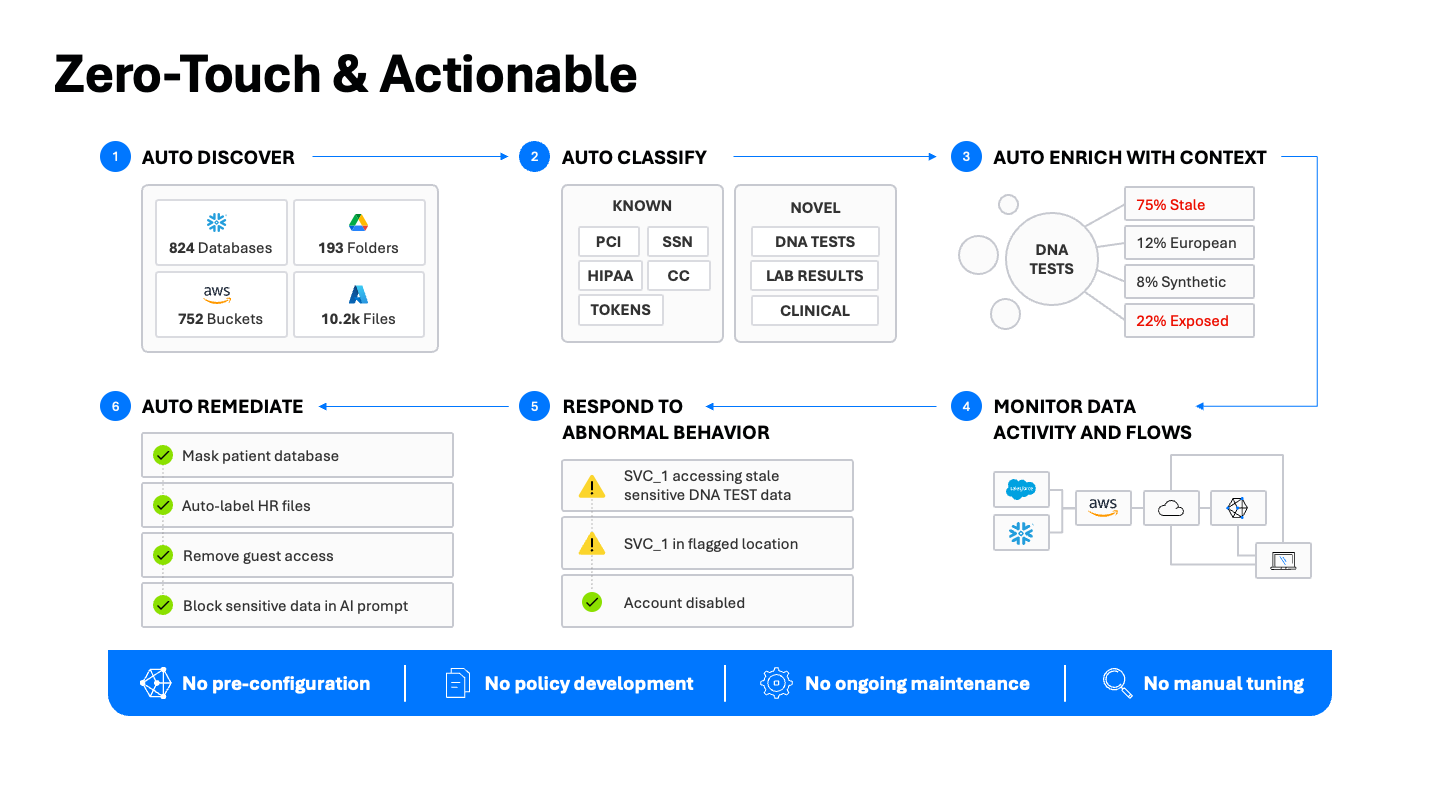
Data discovery and classification aren’t just about visibility. They’re about securing data. The Varonis Data Security Platform delivers an end-to-end approach to data security — from discovery to remediation — designed to reduce manual effort and accelerate security outcomes at every step.
- Auto-discover data stores: Automatically map data across your estate, including cloud, SaaS, and hybrid. Hundreds of databases, thousands of buckets, and countless file shares, all continuously inventoried.
- Auto-classify with the best tool: Start with a comprehensive full scan to establish a baseline, using a blend of pattern-matching, Exact Data Match (EDM), and AI-assisted classification to ensure precision. Then scale efficiently with incremental scanning, leveraging native activity logs to detect changes and scan only what’s new or modified.
- Enrich with context: Go beyond the data type to enrich with subject, topic, and applicable regulations. A file doesn’t just “contain PII.” It contains a “patient intake form containing HIPAA-regulated data.” That context is critical for informing actionable data security.
- Monitor data activity and flows: Maintain a unified audit trail that correlates data, identity, network, and sensitivity telemetry to see how classified data is used, where it moves, and by whom, including AI prompt interactions.
- Respond to abnormal behavior: Accurate classification powers DLP and risk modeling, enabling UEBA to surface complex adversary behaviors. Enrich alerts with classification context to detect exfiltration, insider threats, and AI-tool misuse. Prioritize alerts by blast radius and confidence and accelerate investigations with Varonis 24x7 MDDR.
- Auto-remediate: Classification results need to translate directly into security improvements. This is where automated remediation comes in. Automatically mask sensitive data, auto-label HR files, remove risky guest access, and prevent sensitive data from entering AI prompts without creating unnecessary service tickets or complex integrations.
Our operating principle is firm: There is no pre-configuration, no ongoing policy maintenance, and no manual tuning — just fast, easy deployment and immediate value.
Secure deployment and data residency
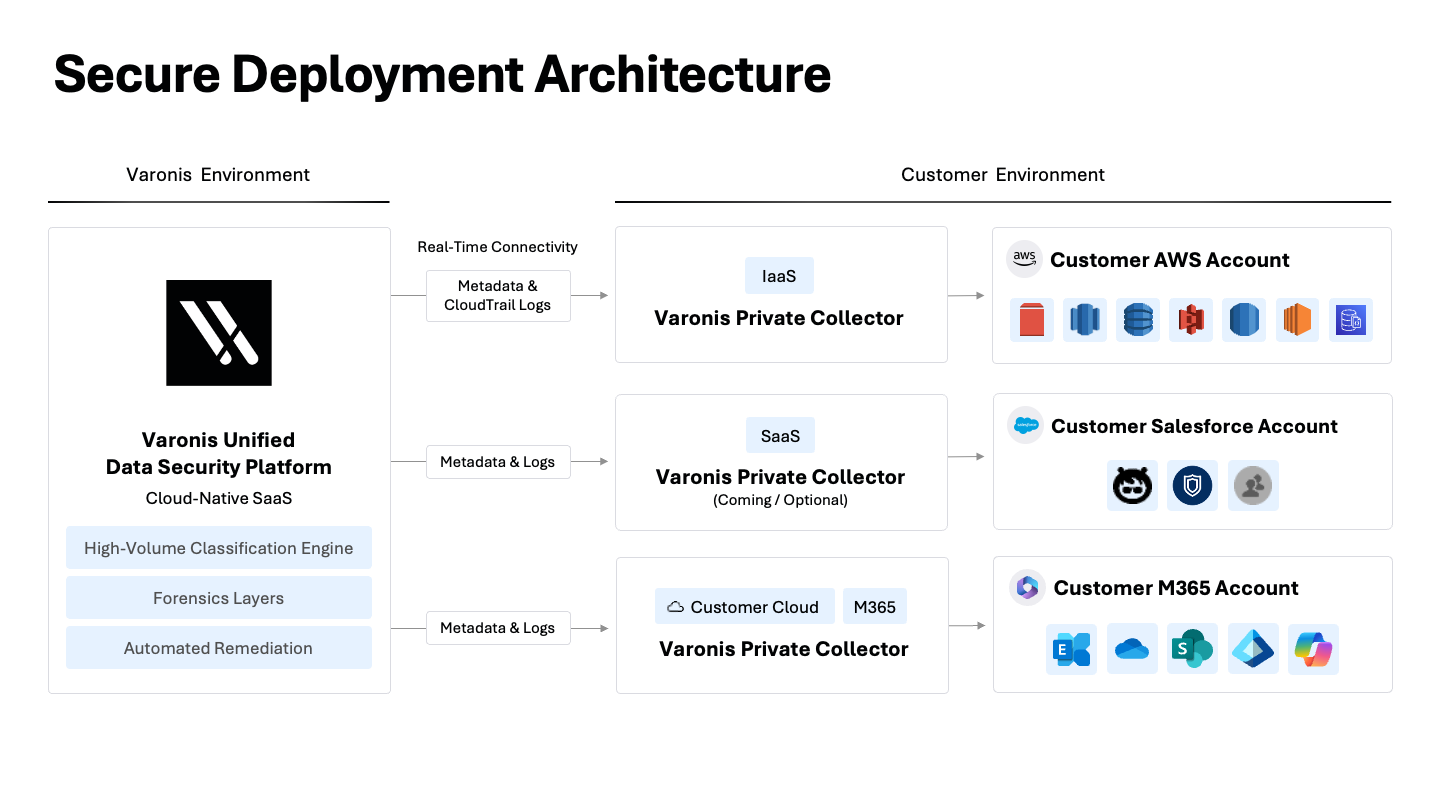
How your data is scanned matters. To help with scale, many vendors transfer your data samples directly to their cloud to be classified. This creates privacy risk, increases your attack surface, and takes away control of your data. If data residency is a concern, direct data transfer should be a non-starter.
Varonis’ approach includes robust tenant isolation, in-region processing to meet data residency requirements, and encryption in transit and at rest. Unlike other vendors, customer data is never used to train our AI models.
For organizations with strict data residency rules, our data collector architecture allows them to process and classify data without ever leaving their environment.
For a deeper look into our security practices, compliance certifications, and privacy policies, we encourage you to visit the Varonis Trust Center.
From classification to control: real-world outcomes
Automated data classification delivers more than just visibility; it enables critical security outcomes. Here’s what that looks like in the real world:
Use case: Tampa General Hospital securely deploys AI
Challenge: Roll out Microsoft 365 Copilot to 10,000 clinical and back-office staff without risking the exposure of sensitive patient data (PHI).
Solution:
- Find the risk: Automatically discovered and classified millions of files containing PHI that were dangerously overexposed.
- Fix the problem: Remediated permissions to a least-privilege model in days, locking down patient data before AI was deployed.
- Alert on data risk: Continuously monitor all data activity and AI prompts post-deployment to detect and stop abnormal access or risky sharing in real time.
Outcome: Tampa General successfully and confidently deployed AI assistants across the organization, enabling innovation while ensuring their most sensitive data remained secure and compliant with HIPAA.
Use case: One of the largest U.S. credit unions deploys enterprise DLP
Challenge:
Deploy DLP controls to protect member PII and payment card data from insider and external threats while ensuring regulatory compliance.
Solution:
- Find the risk: Discovered and classified millions of files containing PII and PCI data, providing the foundation for accurate DLP and exposing widespread open access.
- Fix the problem: Cut open access by 93% through automated least privilege remediation, ensuring only authorized users retain access.
- Alert on data risk: Maintained real‑time oversight of data activity and engaged the Varonis IR team to investigate three separate incidents.
Outcome: The credit union deployed DLP confidently, reducing breach risk while ensuring sensitive member data stayed secure and compliant with regulations like CCPA.
The formula is simple: use precise classification to find what’s at risk, fix what’s exposed, and alert on suspicious activity.
How classification enables safe AI and downstream controls
Data discovery and classification are essential to safely harnessing AI assistants like Microsoft 365 Copilot, ChatGPT Enterprise, and Salesforce Agentforce. You can’t protect what you don’t know. Identifying sensitive data is critical to applying the proper controls and preventing AI from exposing it.
But its impact extends far beyond AI. Accurate classification powers your most critical downstream controls: it adds high-fidelity context to threat detection and response, enables effective DLP, strengthens insider risk programs, and makes data lifecycle automation possible.
Ground-truth classification is how you build adequate guardrails. It ensures sensitive data is protected from exposure or misuse, no matter where it moves or which AI agents you deploy.
Ready to see classification that delivers outcomes?
Stop managing policies and start managing risk. Run a free Data Risk Assessment to get a complete, current, contextual view of your data, plus clear next steps for AI guardrails and DLP.






-1.png)