
The AI classification gold rush
Every data security vendor is racing to put “AI-powered classification” on their marketing materials. It’s the buzzword of the moment, and for good reason — large language models have genuine capabilities that can enhance how we find and categorize sensitive data.
But here’s what the marketing doesn’t tell you: AI classification is a tool, not a strategy. And a tool without the right foundation is just expensive overhead.
I’ve spent nearly two decades watching data security evolve. We started Varonis because we saw a fundamental truth: organizations had no idea what was in their data, who could access it, or who was actually using it. That problem hasn’t gone away. If anything, it’s gotten worse as data has sprawled across cloud services, SaaS applications, and AI-powered collaboration tools.
What has changed is the sophistication of the sales pitch. New entrants to the market are claiming that AI solves everything — that you can throw machine learning at the problem and suddenly your data is protected. That’s not just wrong; it’s dangerous.
The “just regex” straw man
Newer DSPM vendors love to position themselves against “legacy” solutions that rely on “static detection algorithms like regex-based data identifiers.” The implication is clear: regex equals primitive, AI equals modern.
This is a straw man argument, and not a very good one.
We’ve been doing data classification since 2009 — long before anyone was talking about LLMs. Over fifteen years, we’ve built a multi-layered classification engine that combines multiple techniques, each optimized for what it does best.
Calling this approach “regex-based” is like calling a modern automobile “wheel-based.” Technically accurate, fundamentally misleading.
Here’s the thing about deterministic methods like regex with algorithmic verification: they’re right virtually 100% of the time for what they’re designed to detect. A credit card number that passes the Luhn algorithm is a credit card number. There’s no probability involved.
LLMs, by contrast, are probabilistic. The best published research shows that even optimized AI classification achieves 90-95% accuracy in favorable conditions. For some use cases, that’s fine. For compliance, where a missed sensitive file can mean regulatory penalties, it’s not.
The right answer isn’t AI or deterministic — it’s both, each applied where it excels.
Example of a multi-layered classification engine

Example of a multi-layered classification engine
The right way to use AI: inference-only
When we added LLM-based classification to Varonis, we made a deliberate architectural choice: our models run in inference-only mode.
What does that mean? The model analyzes data and returns classifications, but it doesn’t learn from the data it processes. Your sensitive information doesn’t become training data. It doesn’t get “embedded” into model weights. It doesn’t improve the model for other customers.
This matters because many AI-first vendors take a different approach. They tout “auto-learning” capabilities that adapt to each customer’s environment. That sounds impressive until you realize what it means: your data is being used to train their models.
They’ll tell you the data is “embedded in an irreversible way” or “segregated to prevent exposure.” But embedded is still embedded. For regulated industries — financial services, healthcare, government — this isn’t a technical detail. It’s a compliance question your auditors will eventually ask.
There’s also a security risk that doesn’t get enough attention: models that learn from customer data can be interrogated. If an attacker gains access to the model — or if a sophisticated prompt injection technique emerges — they can potentially extract information about what the model has seen. A model that has learned patterns from your sensitive data becomes a target. An inference-only model has nothing to reveal.
How Varonis applies AI classification
Varonis applies AI classification as a core part of a broader classification engine. Within this approach, AI classification is especially effective for topic-level categorization, ambiguous unstructured content, and novel sensitive data types. But for known data types with clear signatures, deterministic methods are still the more efficient and precise choice.
In other words, Varonis uses the right tool for the right job: AI for semantic analysis and discovery, deterministic classification for speed, precision, and scale.
Data sovereignty is non-negotiable
Let’s talk about something most AI-first vendors would rather you not think about: where does your data go during classification?
Many newer DSPM solutions require your data to leave your environment for processing. They describe it as “cloning a snapshot” or using “minimal, protected data samples.” The language is reassuring. The reality is that your sensitive data is traveling to infrastructure you don’t control.
Our approach is different, and it’s non-negotiable: sensitive data never leaves customer environments. Period.
When we use LLMs for classification, they either run locally within the customer’s environment, or any data sent to external models is first obfuscated and sanitized. The actual sensitive values — the names, account numbers, health records — stay where they belong.
Ask your vendor a simple question: “Is my data used to train your AI models?” If the answer requires explanation, you have your answer. And while you’re at it, ask: “What data leaves our environment, where does it go, and who has access to it?”
The sampling problem: what you don’t scan, you don’t know
To achieve fast time-to-perceived-value, some vendors rely heavily on sampling. They'll cluster similar files using machine learning and then classify a small sample from each cluster. It sounds efficient.
Here’s the problem: sampling makes sense for structured data, where schema consistency means a sample is representative. If you look at 1,000 rows of a database table and they all have the same columns, you can reasonably infer what the other million rows contain.
Unstructured data doesn’t work that way.
A file share with 10 million documents might have sensitive data in 0.1% of files — scattered across random locations, in unexpected formats, created by employees who left years ago. If you sample 1% of those files, you’ll miss 99% of the sensitive content. That’s not a rounding error. That’s a compliance gap.
Think about the scenarios that keep CISOs up at night: the spreadsheet with the entire customer database that someone exported three years ago, the PDF with merger documents in a forgotten SharePoint site, the text file with production credentials that a developer created for “temporary” use. These are exactly the files that sampling misses.
Our customers typically choose to classify everything — because they understand that you can’t protect what you haven’t found. Sampling is available as an option, not the default.
Keeping the inventory current: why activity matters
A data inventory is only useful if it’s current. The moment a scan completes, it starts becoming stale. New files are created. Existing files are modified. Permissions change. Data moves.
There are two ways to keep up:
Option 1: Periodic rescanning
Re-crawl your entire environment on a schedule — daily, weekly, monthly. This is resource-intensive, always behind, and misses everything that happens between scans. If someone creates a sensitive file on Tuesday and your scan runs on Sunday, you’ve got a five-day blind spot.
Option 2: Activity monitoring
Track file system events in real time. Know immediately when data is created, modified, moved, or accessed. Trigger classification on new or changed content rather than rescanning everything. Maintain an always-current inventory at a fraction of the compute cost.
This isn’t a close call. Activity monitoring is the only way to maintain a current inventory without burning through compute resources on constant full scans.
There’s another benefit that matters when you’re dealing with petabytes of data: activity lets you prioritize. Instead of scanning everything equally, you can focus your initial classification on the data that’s actually being used — the active, accessed files that represent real risk. The dusty archive that hasn’t been touched in five years can wait. The folder getting heavy traffic from the finance team goes first.
Periodic rescanning leaves organizations with data visibility gaps, while activity monitoring updates immediately.
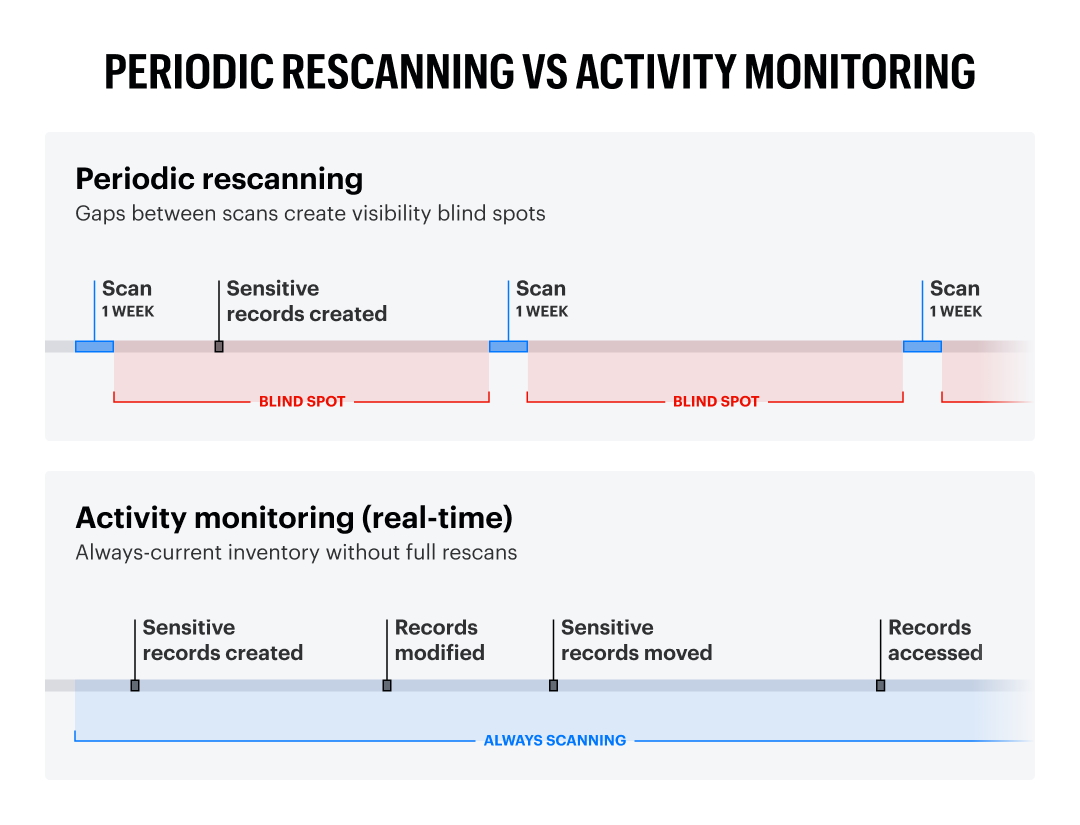
Periodic rescanning leaves organizations with data visibility gaps, while activity monitoring updates immediately.
Activity is the foundation for everything
Here’s what many DSPM vendors miss: activity monitoring isn’t just about keeping your inventory fresh. It’s the foundation for everything else you need to do with your data.
Least privilege: Knowing who can access data is table stakes. The real question is: who actually accesses it? Who needs access versus who has it by accident? You can’t right-size permissions without understanding usage. And you can’t understand usage without activity data.
Threat Detection: Ransomware, exfiltration, insider threats — they all manifest as abnormal activity. A user accessing thousands of files they’ve never touched. A service account suddenly reading sensitive directories. Mass downloads before a resignation. Without activity monitoring, these behaviors are invisible.
AI Abuse Detection: As organizations deploy AI copilots and LLMs, a new threat vector has emerged: prompt abuse. Employees — intentionally or accidentally — asking AI assistants to summarize confidential documents, extract sensitive data, or bypass access controls. You need prompt monitoring to see these interactions and understand what your AI tools are being asked to do with your data.
Think about how your credit card company detects fraud. They don’t periodically scan your card’s permissions. They watch every transaction in real time, looking for anomalies. Data security works the same way. Posture tells you what could happen. Activity tells you what is happening.
Stale Data Identification: Data that no one accesses is data that can be archived or deleted — reducing your attack surface and compliance scope. But you can’t identify stale data without knowing what’s being used.
Access Certification: When an auditor asks “Does this user need access to this data?” you need evidence. Activity data provides that evidence.
A DSPM solution without activity monitoring is like a security camera that only takes photos once a week. You’ll see the before and after, but you’ll miss the crime.
The “posture” problem: where DSPM falls short
Many DSPM vendors talk about “identity access insights” and helping organizations “enforce Zero Trust policies.” It sounds comprehensive. Look closer and you’ll find it’s not.
What most DSPM vendors mean by “posture” is basic configuration settings they can crawl — is MFA enabled? Are there publicly shared links? Is encryption turned on? These settings matter. Getting them right is important. But it’s incomplete and insufficient for actual data protection.
Here’s what they don’t do: real access control analysis. They don’t understand NTFS ACLs. They don’t map folder inheritance. They don’t resolve nested group memberships. They don’t trace the complex identity relationships that actually determine who can touch your sensitive files. They don’t model IAM role inheritance or service principal permissions in cloud environments.
There’s not an ACL to be found in most of these platforms.
When a DSPM vendor tells you they provide “visibility into who has access,” ask them to show you the inheritance chain. Ask them how they handle a user who belongs to a security group that’s nested inside another group that has permissions on a folder three levels up from the sensitive file. If they can’t answer that question, they’re not doing access governance — they’re doing posture checks and calling it something grander.
Understanding access requires deep work: parsing permissions, resolving identities, calculating effective access across complex inheritance hierarchies. We’ve been doing this for nearly twenty years. It’s hard. That’s why most vendors don’t do it.
What to look for in a Data Security Platform
When evaluating data security solutions, here are the questions that matter:
The vendors who struggle with these questions are usually the ones who’ve optimized for demo speed over operational depth. They can show you a dashboard quickly. Whether it reflects reality is another matter.
Maturity over marketing
AI-powered classification is a genuine capability that can add value when applied correctly. But it’s not a substitute for the fundamentals: comprehensive coverage, data sovereignty, activity monitoring, and classification maturity built over years of real-world deployment.
The vendors racing to market with “AI-first” positioning have optimized for speed-to-demo over depth-of-coverage. Their sampling approach delivers fast initial results, but leaves organizations with incomplete visibility, stale inventories, no behavioral baseline for threat detection, and data sovereignty concerns.
We took the harder path: building classification maturity over nearly two decades, adding activity monitoring as a foundational layer, and ensuring data never leaves customer control. The result isn’t just classification — it’s data intelligence that enables protection, detection, and response.
The next time a vendor tells you AI classification will solve all your data security problems, ask them the hard questions. The answers will tell you everything you need to know.







-1.png)