
La ruée vers l'or de la classification de l'IA
Tous les fournisseurs de solutions de sécurité des données s’empressent d’intégrer la « classification assistée par IA » dans leurs supports marketing. C’est le mot à la mode du moment, et pour cause : les grands modèles linguistiques possèdent de réelles capacités qui peuvent améliorer la manière dont nous recherchons et classons les données sensibles.
Mais voici ce que le marketing ne vous dit pas : la classification par IA est un outil, pas une stratégie. Et un outil sans fondement adéquat n’est qu’une dépense coûteuse.
J’ai passé près de deux décennies à observer l’évolution de la sécurité des données. Nous avons créé Varonis parce que nous avons constaté une réalité fondamentale : les entreprises n’avaient aucune idée du contenu de leurs données, des personnes qui y avaient accès ou de celles qui les utilisaient réellement. Ce problème n’a pas disparu. Au contraire, il s’est aggravé à mesure que les données se sont répandues dans les services cloud, les applications SaaS et les outils de collaboration assistés par IA.
Ce qui a changé, c’est la sophistication des arguments de vente. Les nouveaux venus sur le marché prétendent que l’IA résout tous les problèmes, qu’il suffit d’appliquer le machine learning à un problème pour que vos données soient soudainement protégées. Non seulement c’est faux, mais c’est aussi dangereux.
Le faux argument « juste regex »
Les nouveaux fournisseurs de DSPM aiment se positionner contre les solutions « traditionnelles » qui s’appuient sur « des algorithmes de détection statiques tels que les identifiants de données basés sur des expressions régulières ». Le message est clair : regex est primitif, l’IA est moderne.
Il s’agit là d’un argument fallacieux, et pas des plus convaincants.
Nous effectuons la classification des données depuis 2009, bien avant que quiconque ne parle des LLM. En quinze ans, nous avons mis au point un moteur de classification multicouche qui combine plusieurs techniques, chacune optimisée pour ce qu’elle fait le mieux.
Qualifier cette approche de « basée sur les expressions régulières » revient à qualifier une automobile moderne de « basée sur les roues ». Techniquement exact, mais fondamentalement trompeur.
Voici ce qu’il en est des méthodes déterministes telles que les expressions régulières avec vérification algorithmique : elles sont correctes pratiquement 100 % du temps pour ce qu’elles sont conçues à détecter. Un numéro de carte bancaire qui passe l’algorithme de Luhn est un numéro de carte bancaire. Il n’y a aucune probabilité impliquée.
Les LLM, en revanche, sont probabilistes. Les meilleures recherches publiées montrent que même une classification IA optimisée atteint une précision de 90 à 95 % dans des conditions favorables. Pour certains cas d’utilisation, cela suffit. Mais pour la conformité, où un fichier sensible manquant peut entraîner des sanctions réglementaires, ce n’est pas suffisant.
La bonne réponse n’est ni l’IA ni le déterminisme, mais les deux, chacun appliqué là où il excelle.
Exemple d’un moteur de classification à plusieurs niveaux

Exemple d’un moteur de classification à plusieurs niveaux
La bonne façon d’utiliser l’IA : l’inférence uniquement
Lorsque nous avons ajouté la classification basée sur les LLM à Varonis, nous avons fait un choix architectural délibéré : nos modèles fonctionnent en mode inférence uniquement.
Qu’est-ce que cela signifie ? Le modèle analyse les données et renvoie des classifications, mais il n’apprend pas à partir des données qu’il traite. Vos informations sensibles ne deviennent pas des données d’entraînement. Elles ne sont pas « intégrées » dans les poids du modèle. Elles n’améliorent pas le modèle pour d’autres clients.
Cela est important car de nombreux fournisseurs spécialisés dans l’IA adoptent une approche différente. Ils vantent les capacités d’« auto-apprentissage » qui s’adaptent à l’environnement de chaque client. Cela semble impressionnant jusqu’à ce que vous réalisiez ce que cela signifie : vos données sont utilisées pour entraîner leurs modèles.
Ils vous diront que les données sont « intégrées de manière irréversible » ou « séparées pour éviter toute exposition ». Mais intégrées restent intégrées. Pour les secteurs réglementés (services financiers, santé, administration), ce n’est pas un détail technique. C’est une question de conformité que vos auditeurs finiront par vous poser.
Il existe également un risque de sécurité qui n’est pas suffisamment pris en compte : les modèles qui apprennent à partir des données des clients peuvent être interrogés. Si un pirate informatique accède au modèle, ou si une technique sophistiquée d’injection de requêtes apparaît, il peut potentiellement extraire des informations sur ce que le modèle a vu. Un modèle qui a appris des modèles à partir de vos données sensibles devient une cible. Un modèle de type « inference-only » n’a rien à révéler.
La souveraineté des données est non négociable
Parlons d’un sujet que la plupart des fournisseurs spécialisés dans l’IA préféreraient que vous n’abordiez pas : où vont vos données pendant le processus de classification ?
De nombreuses solutions DSPM récentes exigent que vos données quittent votre environnement pour être traitées. Elles décrivent ce processus comme « clonant un instantané » ou utilisant « des échantillons de données minimaux et protégés ». Le langage utilisé est rassurant. En réalité, vos données sensibles sont transférées vers une infrastructure que vous ne contrôlez pas.
Notre approche est différente, et elle n’est pas négociable : les données sensibles ne quittent jamais l’environnement du client. Point final.
Lorsque nous utilisons des LLM pour la classification, ils s’exécutent soit localement dans l’environnement du client, soit les données envoyées à des modèles externes sont d’abord obscurcies et nettoyées. Les valeurs sensibles réelles (noms, numéros de compte, dossiers médicaux) restent là où elles doivent être.
Posez une question simple à votre fournisseur : « Mes données sont-elles utilisées pour entraîner vos modèles d’IA ? » Si la réponse nécessite des explications, vous avez votre réponse. Et tant que vous y êtes, demandez : « Quelles données quittent notre environnement, où vont-elles et qui y a accès ? »
Le problème de l’échantillonnage : ce que vous n’analysez pas, vous ne le connaissez pas.
Pour obtenir rapidement une valeur perçue, certains fournisseurs s’appuient fortement sur l’échantillonnage. Ils regroupent des fichiers similaires à l’aide du machine learning, puis classifient un petit échantillon de chaque groupe. Cela semble efficace.
Voici le problème : l’échantillonnage est pertinent pour les données structurées, où la cohérence du schéma garantit la représentativité d’un échantillon. Si vous examinez 1 000 lignes d’une table de base de données et qu’elles comportent toutes les mêmes colonnes, vous pouvez raisonnablement déduire le contenu des autres millions de lignes.
Les données non structurées ne fonctionnent pas de cette manière.
Un partage de fichiers contenant 10 millions de documents peut contenir des données sensibles dans 0,1 % des fichiers, dispersées à des emplacements aléatoires, dans des formats inattendus, créées par des employés qui ont quitté l’entreprise il y a des années. Si vous échantillonnez 1 % de ces fichiers, vous passerez à côté de 99 % du contenu sensible. Il ne s’agit pas d’une erreur d’arrondi, mais d’une lacune en matière de conformité.
Pensez aux scénarios qui empêchent les RSSI de dormir la nuit : la feuille de calcul contenant l’intégralité de la base de données client que quelqu’un a exportée il y a trois ans, le PDF contenant les documents de fusion dans un site SharePoint oublié, le fichier texte contenant les identifiants de production qu’un développeur a créés pour une utilisation « temporaire ». Ce sont exactement les fichiers que l’échantillonnage ne détecte pas.
Nos clients choisissent généralement de tout classer, car ils comprennent qu’il est impossible de protéger ce qu’ils n’ont pas trouvé. L’échantillonnage est disponible en option, mais n’est pas activé par défaut.
Maintenir l'inventaire à jour : pourquoi l'activité est importante
Un inventaire des données n’est utile que s’il est à jour. Dès qu’uneanalyse est terminée, elle commence à devenir obsolète. De nouveaux fichiers sont créés. Les fichiers existants sont modifiés. Les autorisations changent. Les données sont déplacées.
Il existe deux façons de rester à jour :
Option 1 : nouvelle analyse périodique
Relancez l’exploration de l’ensemble de votre environnement selon un calendrier défini (quotidien, hebdomadaire, mensuel). Cette opération est gourmande en ressources, toujours en retard et passe à côté de tout ce qui se passe entre deux analyses. Si quelqu’un crée un fichier sensible le mardi et que votre analyse s’exécute le dimanche, vous vous retrouvez avec un angle mort de cinq jours.
Option 2 : Suivi des activités
Suivez les événements du système de fichiers en temps réel. Soyez immédiatement informé lorsque des données sont créées, modifiées, déplacées ou consultées. Déclenchez la classification des contenus nouveaux ou modifiés plutôt que de tout rescanner. Maintenez un inventaire toujours à jour à un coût informatique réduit.
Ce n’est pas une décision difficile à prendre. La surveillance des activités est le seul moyen de maintenir un inventaire à jour sans épuiser les ressources informatiques avec des analyses complètes constantes.
Il existe un autre avantage important lorsque vous traitez des pétaoctets de données : l’activité vous permet d’établir des priorités. Au lieu de tout analyser de manière égale, vous pouvez concentrer votre classification initiale sur les données qui sont réellement utilisées, c’est-à-dire les fichiers actifs et consultés qui représentent un risque réel. Les archives poussiéreuses qui n’ont pas été touchées depuis cinq ans peuvent attendre. Le dossier très sollicité par l’équipe financière passe en premier.
Les analyses périodiques laissent aux organisations des lacunes en matière de visibilité des données, tandis que la surveillance des activités se met à jour immédiatement.
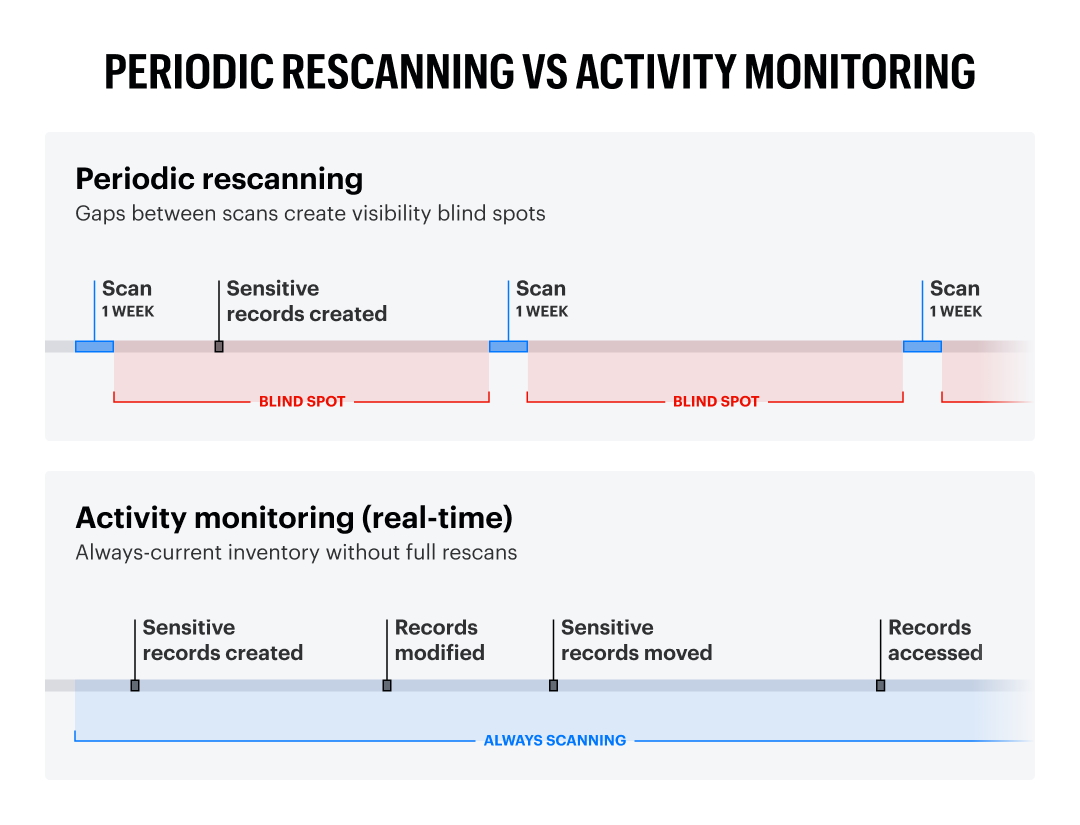
Les analyses périodiques laissent aux organisations des lacunes en matière de visibilité des données, tandis que la surveillance des activités se met à jour immédiatement.
L’activité est la base de tout
Voici ce que beaucoup de fournisseurs de DSPM oublient : la surveillance des activités ne sert pas seulement à garder votre inventaire à jour. C’est la base de tout ce que vous devez faire avec vos données.
Moindre privilège : savoir qui peut accéder aux données est un enjeu crucial. La vraie question est : qui y accède réellement ? Qui a besoin d’y accéder et qui y accède par accident ? Vous ne pouvez pas adapter correctement les autorisations sans comprendre l’utilisation. Et vous ne pouvez pas comprendre l’utilisation sans données d’activité.
Détection des menaces : ransomware, exfiltration, menaces internes — toutes se manifestent par des activités anormales. Un utilisateur accédant à des milliers de fichiers qu’il n’a jamais consultés. Un compte de service lisant soudainement des répertoires sensibles. Des téléchargements massifs avant une démission. Sans surveillance des activités, ces comportements sont invisibles.
Détection des abus liés à l’IA : à mesure que les organisations déploient des copilotes IA et des LLM, un nouveau vecteur de menace est apparu : les requêtes abusives. Les employés demandent, intentionnellement ou accidentellement, aux assistants IA de résumer des documents confidentiels, d’extraire des données sensibles ou de contourner les contrôles d’accès. Vous avez besoin d’une surveillance des requêtes pour voir ces interactions et comprendre ce que vos outils IA sont amenés à faire avec vos données.
Pensez à la manière dont votre société de carte bancaire détecte les fraudes. Elle ne vérifie pas périodiquement les autorisations de votre carte. Elle surveille chaque transaction en temps réel, à la recherche d’anomalies. La sécurité des données fonctionne de la même manière. La posture vous indique ce qui pourrait arriver. L’activité vous indique ce qui est en train de se passer.
Identification des données obsolètes : les données auxquelles personne n’accède peuvent être archivées ou supprimées, ce qui réduit votre surface d’attaque et votre champ d’application en matière de conformité. Mais vous ne pouvez pas identifier les données obsolètes sans savoir quelles sont celles qui sont utilisées.
Certification d’accès : lorsqu’un auditeur demande « Cet utilisateur a-t-il besoin d’accéder à ces données ? », vous devez fournir des preuves. Les données d’activité fournissent ces éléments.
Une solution DSPM sans surveillance des activités, c’est comme une caméra de sécurité qui ne prend des photos qu’une fois par semaine. Vous verrez l’avant et l’après, mais vous passerez à côté du crime.
Le problème de la « posture » : là où le DSPM montre ses limites
De nombreux fournisseurs de DSPM parlent d’« informations sur les accès identitaires » et aident les organisations à « appliquer des politiques zero trust ». Cela semble complet. Mais en y regardant de plus près, on constate que ce n’est pas le cas.
Ce que la plupart des fournisseurs de DSPM entendent par « posture », ce sont les paramètres de configuration de base qu’ils peuvent crawler : l’authentification multifactorielle (MFA) est-elle activée ? Existe-t-il des liens partagés publiquement ? Le chiffrement est-il activé ? Ces paramètres sont importants. Il est essentiel de les configurer correctement. Mais cela reste incomplet et insuffisant pour assurer une protection réelle des données.
Voici ce qu’ils ne font pas : une véritable analyse du contrôle d’accès. Ils ne comprennent pas les ACL NTFS. Ils ne cartographient pas l’héritage des dossiers. Ils ne résolvent pas les appartenances à des groupes imbriqués. Ils ne tracent pas les relations d’identité complexes qui déterminent réellement qui peut accéder à vos fichiers sensibles. Ils ne modélisent pas l’héritage des rôles IAM ni les autorisations des principaux services dans les environnements cloud.
La plupart de ces plateformes ne disposent pas d’ACL.
Lorsqu’un fournisseur DSPM vous dit qu’il offre «
une visibilité sur les personnes qui ont accès
», demandez-lui de vous montrer la chaîne d’héritage. Demandez-lui comment il gère un utilisateur appartenant à un groupe de sécurité imbriqué dans un autre groupe disposant d’autorisations sur un dossier situé trois niveaux au-dessus du fichier sensible. S’il ne peut pas répondre à cette question, c’est qu’il ne fait pas de gouvernance des accès, mais plutôt des contrôles de posture qu’il présente comme quelque chose de plus ambitieux.
Comprendre l’accès nécessite un travail approfondi : analyser les autorisations, résoudre les identités, calculer l’accès effectif à travers des hiérarchies d’héritage complexes. Nous faisons cela depuis près de vingt ans. C’est difficile. C’est pourquoi la plupart des fournisseurs ne le font pas.
Ce qu'il faut rechercher dans une plateforme de sécurité des données
Lors de l’évaluation des solutions de sécurité des données, voici les questions qui importent :
Les fournisseurs qui peinent à répondre à ces questions sont généralement ceux qui ont privilégié la rapidité de démonstration au détriment de la profondeur opérationnelle. Ils peuvent vous montrer rapidement un tableau de bord. Quant à savoir s’il reflète la réalité, c’est une autre histoire.
La maturité plutôt que le marketing
La classification assistée par IA est une fonctionnalité authentique qui peut apporter une valeur ajoutée lorsqu’elle est utilisée correctement. Mais elle ne remplace pas les principes fondamentaux : couverture complète, souveraineté des données, surveillance des activités et maturité de la classification acquise au fil des années de déploiement dans le monde réel.
Les fournisseurs qui se précipitent sur le marché avec un positionnement « AI-first » ont optimisé la rapidité de démonstration au détriment de la profondeur de couverture. Leur approche par échantillonnage fournit des résultats initiaux rapides, mais laisse les organisations avec une visibilité incomplète, des inventaires obsolètes, aucune base de référence comportementale pour la détection des menaces et des préoccupations en matière de souveraineté des données.
Nous avons choisi la voie la plus difficile : développer une maturité en matière de classification pendant près de deux décennies, ajouter la surveillance des activités comme couche fondamentale et veiller à ce que les données restent sous le contrôle des clients. Le résultat n’est pas seulement une classification, mais une intelligence des données qui permet la protection, la détection et la réponse.
La prochaine fois qu’un fournisseur vous dira que la classification par IA résoudra tous vos problèmes de sécurité des données, posez-lui des questions difficiles. Les réponses vous diront tout ce que vous devez savoir.






