Databases and data warehouses store vast amounts of sensitive information, making them prime targets for attackers. One of the most effective strategies to mitigate exposure risks and lock down data is data masking, which enables organizations to protect their data by obfuscating it or replacing it with dummy data, rendering it useless to unauthorized users.
With the sheer amount of data being produced by both humans and machines (through AI), data masking prevents threat actors from exploiting sensitive information such as personal identifiers, financial records, or proprietary business data.
Data masking helps organizations:
- Discover and classify sensitive data in databases and data warehouses at scale
- Identify unmasked sensitive columns
- Create, apply, and manage automated masking policies
In this article, we’ll explore the importance of data masking and how organizations can automatically and intelligently mask their critical data and enforce least privilege access.
What is data masking?
Data masking is a process used to temporarily create a structurally similar but inauthentic version of an organization’s data. This technique helps protect sensitive information, ensure least privilege access, and comply with data regulations while retaining the original data’s properties and usability.
By disguising sensitive information, organizations can reduce the risks of data breaches. This is especially crucial when dealing with highly sensitive and regulated information like PII, PCI, PHI, and other sensitive data categories that are prime targets for hackers and subject to regulations.
Data masking is also crucial when developing and training custom AI models. Proper data masking enforcement prevents the unintentional use of regulated data in AI training, which can violate privacy laws and erode customer trust.
Why data masking matters more than ever
As data volumes grow and environments become more complex, the risks associated with exposing sensitive information have skyrocketed. Organizations today face a perfect storm: a relentless rise in cyberattacks, the proliferation of cloud-based services, and increasingly strict data privacy regulations.
The expanding threat landscape
Data breaches are no longer rare: they’re routine. Threat actors now target not just production systems but also development, testing, and analytics environments, where sensitive data is often less protected. Insider threats, whether accidental or malicious, further increase the risk of unauthorized exposure.
Cloud and SaaS adoption
The shift to the cloud has dramatically increased the number of places where sensitive data resides. Companies often replicate production data across dev/test environments, analytics platforms, and third-party tools, which creates multiple points of vulnerability. Data masking helps reduce exposure by ensuring that even if data is accessed, it’s unreadable and unusable.
Regulatory compliance pressure
Laws like GDPR, HIPAA, CCPA, and PCI DSS require organizations to minimize exposure of personally identifiable information (PII) and sensitive financial or health data. Noncompliance can lead to significant fines and reputational damage. Data masking is a recognized method to meet these requirements, especially when using production-like data for non-production purposes.
Why masking, not just encryption
While encryption protects data at rest and in transit, it often doesn’t solve the problem of internal access or test data usage. Masking, on the other hand, provides persistent obfuscation, making it ideal for scenarios where real data is not required but realistic structure and behavior are.

Data masking best practices
It's critical to follow a strategic, policy-driven approach to get the most value from data masking and ensure it supports your broader security and compliance goals. Below are key best practices to help you implement masking effectively and sustainably across your organization.
Start with data discovery and classification
You can’t protect what you can’t see. Begin by identifying where sensitive data lives across your environments, whether it’s in structured databases, unstructured file stores, or SaaS platforms. Use automated data discovery and classification tools to tag data types like PII, PHI, or PCI.
Prioritize based on sensitivity and risk
Not all data requires masking. Focus on high-risk data that is subject to regulatory controls or frequently replicated to lower-security environments. Develop masking policies aligned to the sensitivity of the data and its usage context.
Maintain referential integrity
Ensure that masked data retains its structural relationships across tables and systems. For example, if two datasets share a customer ID, the masked ID should be consistent across both. This preserves data usability for development, testing, and analytics.
Automate and scale masking
Manual masking doesn’t scale and is prone to human error. Use tools that support automation, policy enforcement, and integration with CI/CD pipelines. This ensures consistent masking during data provisioning, migration, and testing workflows.
Choose the right masking technique
Different data types and use cases require different masking approaches. Use substitution or shuffling for names and emails, tokenization for IDs, and format-preserving masking for credit card numbers or dates. Apply deterministic or dynamic masking based on access levels and user roles.
Audit and monitor access to masked data
Even masked datasets can be misused if access isn’t controlled. Apply role-based access controls (RBAC), log usage, and monitor how and where masked data is being consumed, especially in development, staging, or third-party environments.
Review and update masking policies regularly
Data environments evolve quickly. Regularly revisit your masking policies to reflect changes in data structure, sensitivity, and compliance requirements. Periodic reviews also help identify any gaps or outdated rules.
The role of accurate data classification in data masking
Accurate data classification serves as the foundation for effective data masking. Organizations need to know where sensitive data resides to implement comprehensive protection strategies.
Proper classification identifies and prioritizes all sensitive information, such as PHI, PCI, PII, and GDPR data, for masking. By accurately mapping the data landscape at scale, security teams can establish targeted masking policies that protect critical data from breaches and help maintain compliance with stringent regulations.
How Varonis dynamic data masking works
Varonis’ Data Security Platform automatically and dynamically masks data in popular databases and data warehouses, such as Amazon Redshift, Google BigQuery, and Snowflake. This capability helps organizations secure critical structured and semi-structured data and reduce the risk of compromise.
Here's how it works:
Automatically discover and classify sensitive data
Varonis automatically scans each database instance down to the individual column and row level. The Varonis Data Security Platform uses a combination of AI-powered and rule-based classification to quickly and accurately identify sensitive data at scale.
By doing so, Varonis provides a complete and detailed view of where sensitive data resides within your environment. Classification results appear in an intuitive tree view, which shows where sensitive data is concentrated across database instances, schemas, tables, and columns.
Automatically discover and classify sensitive data at scale.
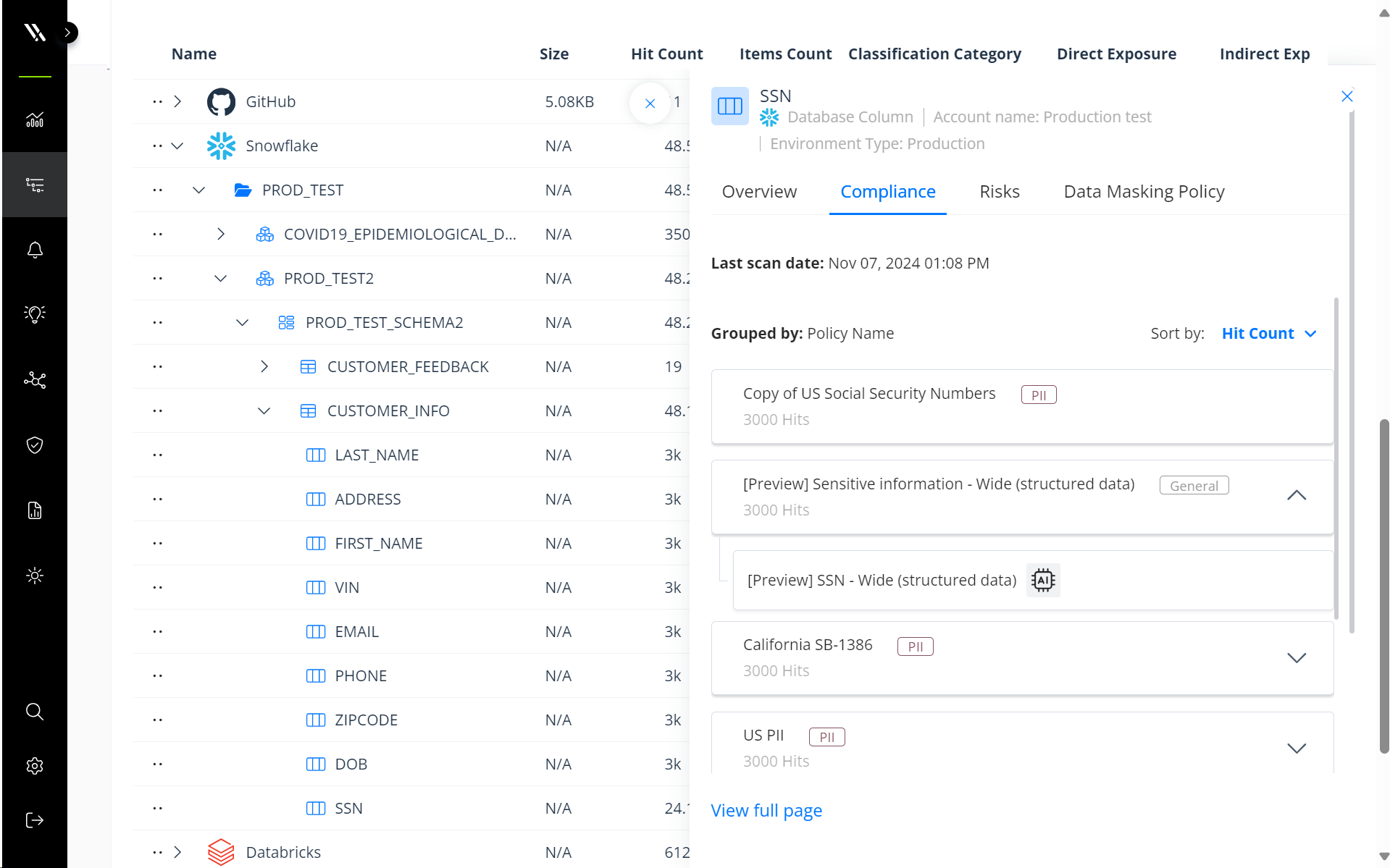
Automatically discover and classify sensitive data at scale.
Identify unmasked sensitive data
Varonis offers out-of-the-box reports that surface unmasked columns with sensitive data. These reports automatically update as Varonis completes its scans and can be sent to stakeholders regularly for review.
Identify unmasked sensitive columns.
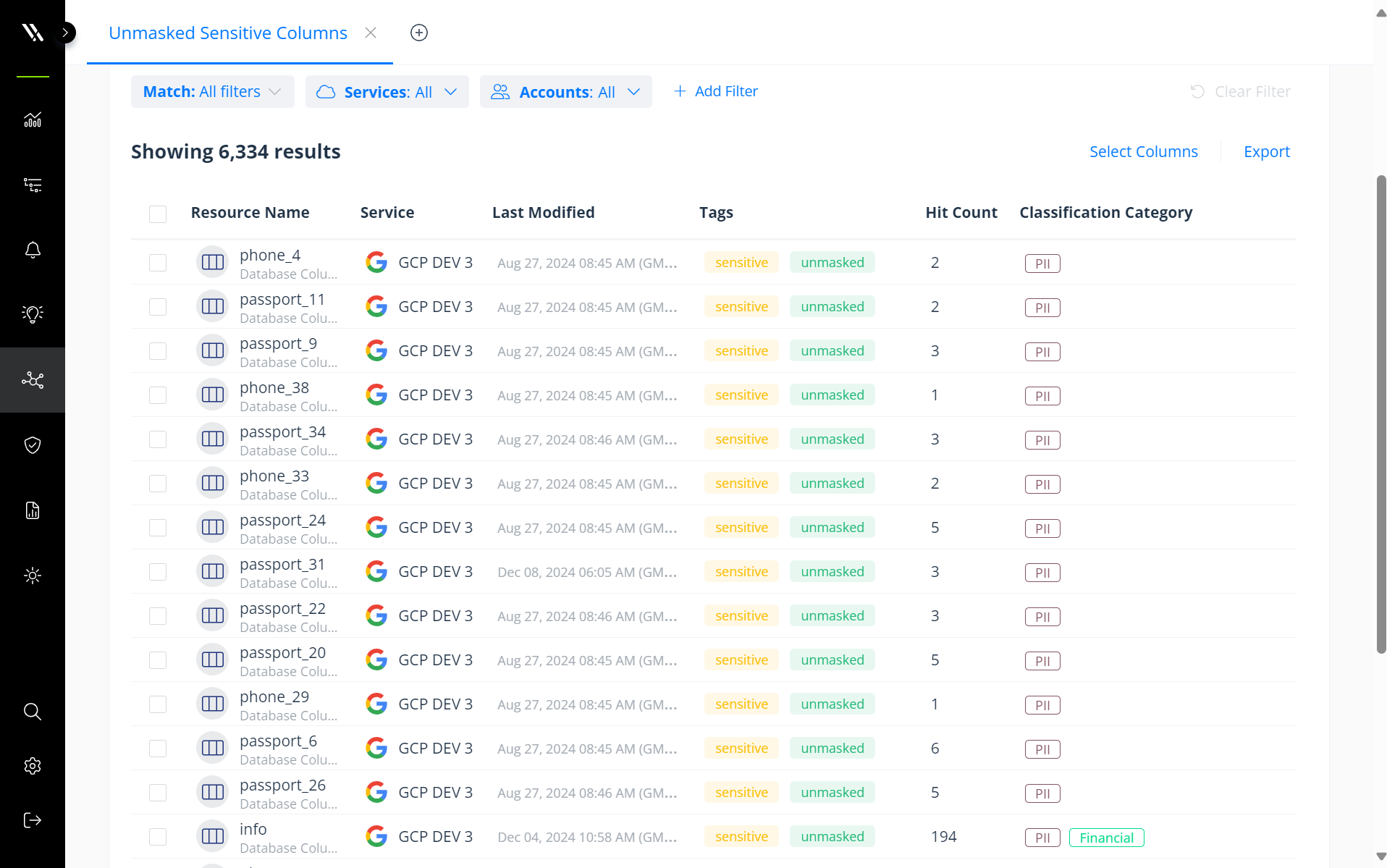
Identify unmasked sensitive columns.
Create and apply automated masking policies
From the unmasked data report, security teams can use Varonis’ powerful policy engine to create and apply automated dynamic masking policies.
To apply the masking policies, you simply name the policy, select the masking type, and execute it. Varonis will then intelligently apply the masks to all relevant columns, ensuring that when users access this data within the targeted platform, they will only receive the masked information.
These policies can also be configured to exclude roles authorized to view unmasked data. This helps ensure that critical data is locked down and that least privilege is enforced without impeding business operations.
Configure automated masking policies.
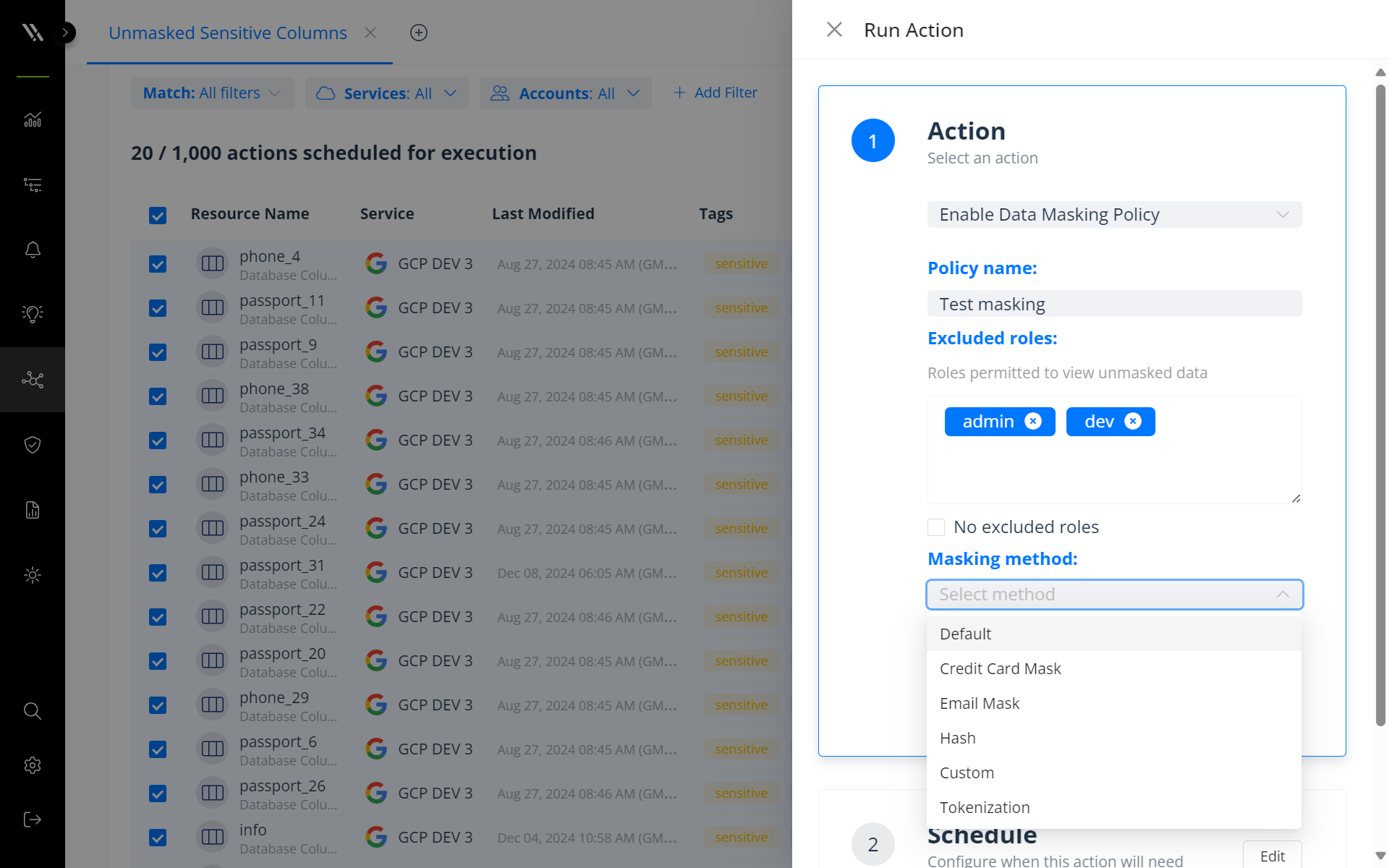
Configure automated masking policies.
Varonis uses intelligent, dynamic masking based on column type and supports masking methods such as:
- Credit card masking
- Email masking
- Tokenization
- Hashing
You can also create custom masks that replace data with end-user-provided text.
Once you’ve implemented your masking policies, Varonis provides a comprehensive view of all resources protected by each policy and an overview of every masking policy applied to a single schema, table, or column. This view helps you confirm that you’ve correctly applied your masking policies and secured your data.
Review the resources protected by specific masking policies.
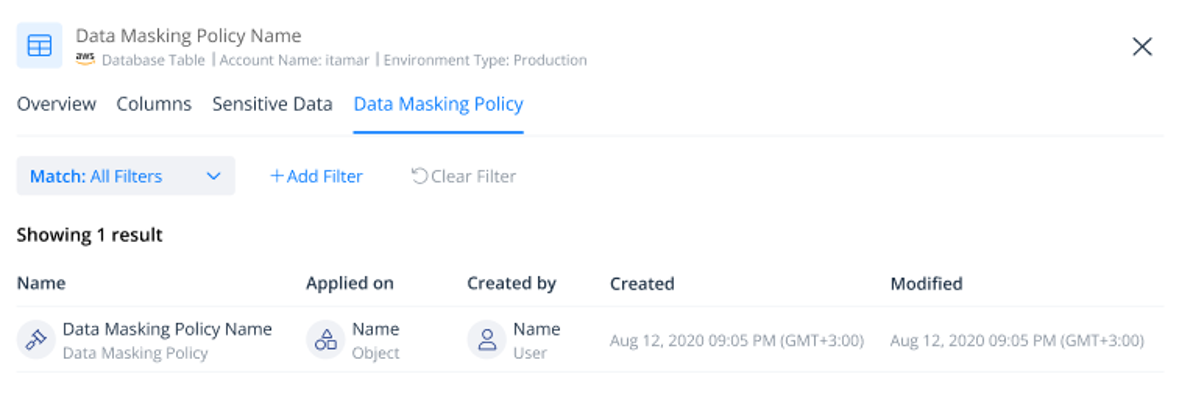
Review the resources protected by specific masking policies.
Removing Varonis-applied data masks
Varonis allows you to remove or modify data masks as needed. You can unmask specific columns automatically or manually or update existing masking policies with new ones. This enables you to manage your data masking policies with flexibility and ease.
FAQs about dynamic data masking
What is dynamic data masking and why is it important for data security?
Dynamic data masking temporarily creates structurally similar but inauthentic versions of sensitive data. It protects information by obfuscating or replacing it with dummy data while preserving the original data's properties. This technique is crucial for organizations handling PII, PCI, PHI, and other regulated data categories. Dynamic data masking helps enforce least privilege access and ensures compliance with data regulations without affecting data usability.
What role does data classification play in effective data masking?
Accurate data classification forms the foundation for implementing comprehensive data masking strategies. It helps organizations identify and prioritize where sensitive information resides before applying protection measures. By mapping the data landscape at scale, security teams can establish targeted masking policies for critical data. Proper classification ensures that all regulated data types are appropriately masked, helping maintain compliance with privacy regulations.
How does dynamic data masking support AI security and development?
Dynamic data masking prevents the unintentional use of regulated data in AI training processes. This protection is vital as organizations develop and train custom AI models that could potentially violate privacy laws. By ensuring sensitive information is properly masked, companies can maintain customer trust while still leveraging data for innovation. This capability helps organizations balance AI advancement with necessary data protection and regulatory compliance.
How does Varonis implement dynamic data masking across different database platforms?
Varonis automatically scans database instances down to individual column and row levels. The platform uses AI-powered and rule-based classification to identify sensitive data at scale across Amazon Redshift, Google BigQuery, and Snowflake. Varonis offers intelligent masking methods, including credit card masking, email masking, tokenization, and hashing. Users can configure automated masking policies that exclude authorized roles while ensuring sensitive data remains protected.
What management capabilities does Varonis provide for data masking policies?
Varonis offers comprehensive visibility into all resources protected by each masking policy. Users can view every masking policy applied to specific schemas, tables, or columns in an intuitive interface. The platform allows flexibility to remove or modify data masks as needed, either automatically or manually. Varonis provides out-of-the-box reports that surface unmasked columns with sensitive data, which automatically update as scans complete.